Twój koszyk jest obecnie pusty!
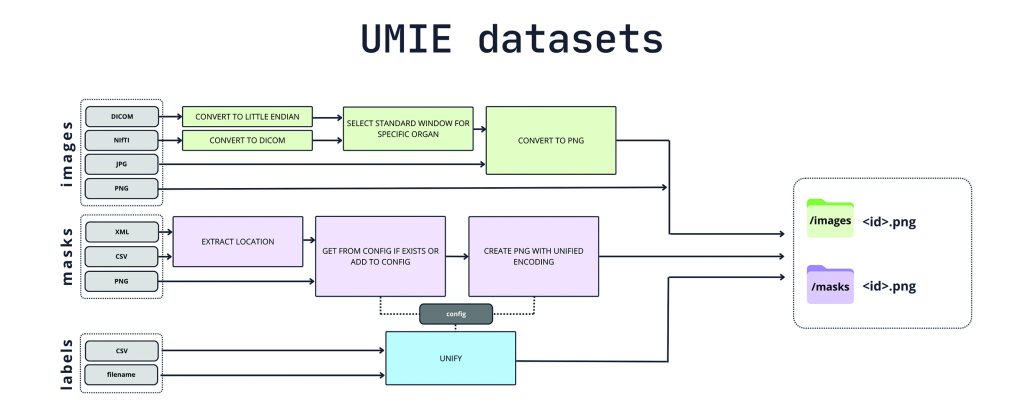
UMIE datasets: milion obrazów dla AI
Naukowcy z interdyscyplinarnej grupy badawczej TheLion.AI, kierowanej przez Barbarę Klaudel, opublikowali największy na świecie zbiór danych obrazowania diagnostycznego o nazwie UMIE (Universal Medical Image Encoder) datasets. Projekt ten łączy ponad milion obrazów medycznych z 20 otwartych źródeł i obejmuje obrazy CT, MRI i rentgenowskie wielu narządów. Każdy obraz posiada etykietę lub/i maskę segmentacyjną. Projekt ma rozwiązywać problemy z dostępnością i standaryzacją danych medycznych, które hamują rozwój modeli fundacyjnych w medycynie. Grupa badawcza udostępniła również narzędzia do przetwarzania nowych zbiorów danych, które umożliwiają łatwe rozszerzanie datasetu. Projekt jest obecnie w fazie alfa i zostanie wkrótce udostępniony na platformie HuggingFace, by stworzyć nowe możliwości dla badaczy i praktyków w dziedzinie medycznej AI.
Autentyczność nagrań głosowych
Najnowsze badania w dziedzinie autentyczności głosu, autorstwa m.in. Piotra Kawy, badacza z Politechniki Wrocławskiej, przynoszą istotne innowacje, które mogą zrewolucjonizować sposób, w jaki identyfikujemy i analizujemy nagrania dźwiękowe. W pierwszym z nich, zatytułowanym MLAAD: The Multi-Language Audio Anti-Spoofing Dataset, naukowcy stworzyli wielojęzyczny zbiór danych, który ma na celu przeciwdziałanie oszustwom głosowym. Zbiór ten obejmuje 160,2 godziny nagrań syntetycznego głosu mówiącego w 23 językach, generowanego przy użyciu 52 modeli syntezatorów mowy opartych na 22 różnych architekturach. Drugi artykuł, A New Approach to Voice Authenticity, proponuje zupełnie nowe podejście do kwestii autentyczności nagrań głosowych. Zamiast dotychczasowego podziału na dźwięki „prawdziwe” i „fałszywe” wprowadzono koncepcję identyfikowania „edycji głosu”. Metody te, podzielone na sześć kategorii, obejmują zarówno nowoczesne techniki, takie jak syntezowanie mowy i przekształcanie głosu, jak i tradycyjne manipulacje, takie jak filtry, zniekształcenia, cięcia i zmiany prędkości. Nawet prosta zmiana, jak spowolnienie dźwięku czy źle dobrana korekcja, może znacząco wpłynąć na postrzeganie autentyczności i wiarygodności mówcy.
ProvenView: rewolucja w weryfikacji autentyczności rozmów online
Naukowcy z IDEAS NCBR opracowali prototypowe oprogramowanie ProvenView, które może zrewolucjonizować sposób weryfikacji wiarygodności rozmów online. Projekt, stworzony przez Shahriara Ebrahimiego i Parisę Hassanizadeh pod kierownictwem prof. Stefana Dziembowskiego, wykorzystuje technologię Zero-Knowledge Proofs (ZKP) do autoryzacji bez pośrednika. ProvenView umożliwia tworzenie cyfrowego dowodu autentyczności nagrania, który można później zweryfikować bez konieczności oglądania całego materiału. To innowacyjne rozwiązanie zostało nagrodzone podczas hackathonu ZK Hack Kraków w maju 2024 roku. Profesor Dziembowski podkreśla znaczenie tego projektu: „Technologia Zero-Knowledge Proofs jeszcze dekadę temu uważana była za dziedzinę wyłącznie teoretyczną, bliższą czystej matematyce niż zastosowaniom informatyki. W ostatnich latach byliśmy świadkami dramatycznej zmiany w tej dziedzinie. Stało się to dzięki wielu przełomowym usprawnieniom tej technologii, a także dzięki jej popularyzacji za sprawą blockchaina. Rozwiązanie ProvenView stanowi jeszcze jeden spektakularny przykład tego, jak ZKP może być wykorzystywane w walce z zagrożeniami współczesnego świata cyfrowego”. Choć ProvenView jest obecnie w fazie eksperymentalnej, wszystko wskazuje na to, że takie metody mogą znaleźć praktyczne zastosowanie w przyszłości.

POLygraph – polskie narzędzie do wykrywania fake newsów
Naukowcy z Uniwersytetu Adama Mickiewicza w Poznaniu opracowują przełomowe narzędzie do wykrywania fake newsów tworzonych w języku polskim. Projekt POLygraph, który wykorzystuje zaawansowane metody przetwarzania języka naturalnego i big data, ma szansę zrewolucjonizować walkę z dezinformacją w polskim internecie. Kluczem do sukcesu są obszerne bazy danych: fake-or-not z ponad 11 tysiącami par artykułów oraz fake-they-say z 5 tysiącami artykułów i komentującymi je tweetami. Innowacyjne podejście polega na analizie nie tylko samych wiadomości, ale też reakcji użytkowników, co pozwala lepiej zrozumieć mechanizmy rozprzestrzeniania się fake newsów. W lipcu 2024 roku zespół opublikował na arxiv.org artykuł POLygraph: Polish Fake News Dataset, który prezentował metodologię i wstępne wyniki badań. To ważny krok w kierunku transparentności i udostępnienia cennego zasobu badaczom zajmującym się dezinformacją w kontekście polskojęzycznym.

Przełomowe badanie nad estymacją LID
Naukowcy z kilku czołowych instytucji badawczych, w tym Uniwersytetu Warszawskiego, NASK, Snowflake oraz ETH Zurich, opublikowali przełomowe badanie dotyczące metod estymacji lokalnego wymiaru wewnętrznego (LID) danych. Artykuł pod tytułem A Wiener process perspective on local intrinsic dimension estimation methods prezentuje nowatorskie spojrzenie na istniejące algorytmy poprzez pryzmat procesu Wienera. Głównym celem badania jest analiza nowych, parametrycznych metod estymacji LID, które wykorzystują modele generatywne do aproksymacji gęstości danych.
Umożliwia to skalowanie do zbiorów o wysokiej wymiarowości, takich jak obrazy. Autorzy – Piotr Tempczyk, Łukasz Garncarek, Dominik Filipiak oraz Adam Kurpisz – wskazują, że dodanie szumu gaussowskiego do danych można interpretować jako badanie ewolucji procesu Wienera, który opisuje dyfuzję cząstek w przestrzeni. Badacze przeanalizowali zachowanie nowoczesnych algorytmów w różnych warunkach, a także błędy, które algorytmy popełniają w zależności od gęstości prawdopodobieństwa danych.
Efektem jest dokładniejsze matematyczne opisanie tych metod oraz identyfikacja kluczowych parametrów, które wpływają na ich wydajność. Artykuł wyróżnia się również wprowadzeniem nowych kategorii algorytmów estymacji LID bazujących na procesie Wienera: algorytmów izolowanych i holistycznych. Podział ten umożliwia lepsze zrozumienie i klasyfikację istniejących oraz przyszłych metod. Wyniki badań mogą znacząco wpłynąć na dalszy rozwój algorytmów uczenia maszynowego, zwłaszcza w kontekście analizy danych wysokowymiarowych i wykrywania anomalii. Praca ta stanowi ważny krok naprzód w dziedzinie analizy topologicznej danych i estymacji wymiarowości.

Wczesne diagnozowanie choroby Alzheimera dzięki sztucznej inteligencji
Naukowcy z Uniwersytetu Medycznego we Wrocławiu oraz z Uniwersytetu Bostońskiego opracowali pionierską metodę wczesnego diagnozowania i prognozowania choroby Alzheimera. Poprzez wykorzystanie sztucznej inteligencji do analizy mowy pacjenta badacze stworzyli nowe możliwości walki z tą podstępną chorobą. Wrocławski zespół opracował innowacyjne narzędzie diagnostyczne, które wymaga jedynie 10-sekundowego nagrania pacjenta wymawiającego samogłoskę „a”. Naukowcy dążą do tego, aby ich narzędzie diagnostyczne trafiło na smartfony, by umożliwić szerokiemu gronu odbiorców wczesne wykrycie choroby bez ponoszenia znacznych nakładów finansowych.


Share
You might be interested in
-
CampusAI koproducentem filmu „Mistrz” o nauczycielu geniuszy AI
W piątek w warszawskiej Rotundzie odbyła się premiera dokumentu „Mistrz”. Filmu, który jest hołdem dla Ryszarda Szubartowskiego – człowieka, który wychował prekursorów generatywnej sztucznej inteligencji.

-
CampusAI patronem medialnym konferencji I💚AI
Już na początku kwietnia odbędzie się kolejna edycja konferencji I💚Marketing & Technology. Pierwszego dnia wydarzenia prelegenci i prelegentki skupią się na sztucznej inteligencji oraz na analityce w reklamie. Czego jeszcze można się…

-
Me+AI: Graduation Day
Każdy z nas ma z tyłu głowy pomysły, które czekają na swoją chwilę. Czasami jest to nienapisana książka, innym razem projekt dotyczący inwestowania. W CampusAI takie koncepcje nabierają kształtów i często przeradzają…

-
Ekosystem innowacji rośnie w siłę
CampusAI to przestrzeń, w której innowacja spotyka się z praktyką, a społeczność buduje przyszłość sztucznej inteligencji. Każdego dnia obserwujemy, jak nasza wizja demokratyzacji sztucznej inteligencji nabiera realnych kształtów. Tworzymy ekosystem, który rośnie…