Twój koszyk jest obecnie pusty!
YOLO – jeden rzut oka wystarczy
Wyglądając ze znudzenia przez okno, w ułamku sekundy nasz mózg zidentyfikuje przejeżdżającego na hulajnodze biznesmena w garniturze, panią wyprowadzającą na smyczy pudelka czy sfrustrowanego kuriera, który nie może znaleźć adresu zamówienia.
To, co nam wydaje się naturalne i oczywiste, dla komputerów przez długie lata stanowiło nie lada wyzwanie.
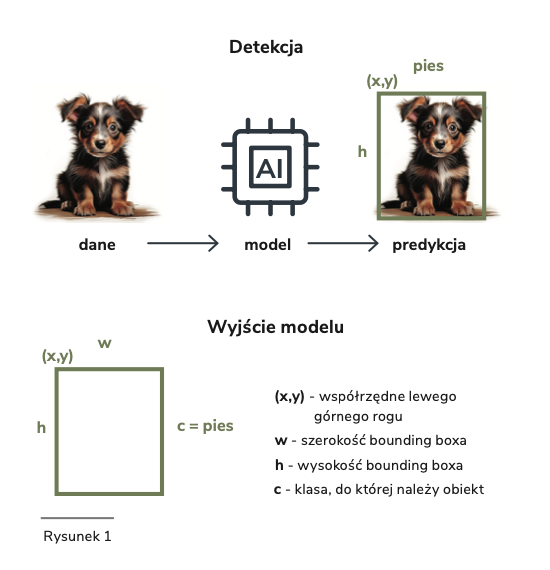
Detekcja obiektów to proces, w którym algorytm musi wykonać dwa kluczowe zadania: zidentyfikować obiekty na obrazie oraz precyzyjnie określić ich położenie (Rysunek 1). Wyzwanie polega na tym, że system musi radzić sobie z ogromnym zróżnicowaniem wizualnej reprezentacji tych samych obiektów – bo przecież dom, człowiek, pies, garnitur mogą mieć tysiące różnych wariantów. Kolejnym problemem jest zmienność tego samego obiektu, która wynika z kilku głównych czynników: różnych kątów patrzenia (na przykład pies widziany z różnych stron), zmiennych warunków oświetleniowych wpływających na rozkład cieni, częściowego zasłaniania obiektów (jak dziecko częściowo schowane za drzewem), różnic w rozmiarze obiektów w kadrze oraz zmiennego tła (przykładowo ławka na trawniku versus ta sama ławka na betonowym placu). Co więcej, najlepiej, żeby wszystkie te analizy odbywały się błyskawicznie, żeby system mógł działać w czasie rzeczywistym.
W 2015 roku zespół naukowców z University of Washington przedstawił przełomowe rozwiązanie tego problemu. Joseph Redmon wraz ze współpracownikami opublikował artykuł opisujący system YOLO (You Only Look Once, „patrzysz tylko raz”), który zrewolucjonizował dziedzinę detekcji obiektów w obrazach. Do tej pory dostępne modele analizowały obraz fragment po fragmencie. Popularnym podejściem było tzw. sliding window (przesuwane okno). Model analizował obraz kawałek po kawałku, jakby przesuwał lupę po fotografii. To działało, ale było bardzo czasochłonne – trzeba było przeanalizować tysiące małych fragmentów obrazu, często wielokrotnie, w różnych skalach. Inną metodą było dwuetapowe podejście (modele typu RCNN). Najpierw algorytm proponował potencjalne lokalizacje obiektów („Tu może być coś interesującego”). Następnie inny algorytm próbował klasyfikować znalezione obszary („To wygląda jak pies”). Ten proces był również powolny i często zawodny.
YOLO zaproponowało zupełnie inne podejście – spojrzenie na całość obrazu jednym rzutem oka, podobnie jak robi to człowiek. Wcześniejsze systemy detekcji obiektów potrzebowały kilku, a nawet kilkunastu sekund na przeanalizowanie pojedynczego zdjęcia. YOLO potrafiło to zrobić w czasie rzeczywistym, analizując aż 45 klatek na sekundę. To właśnie ta szybkość, w połączeniu z wysoką skutecznością, sprawiła, że architektura YOLO stała się tak popularna i jej udoskonalone wersje znajdziemy w autonomicznych pojazdach, systemach do monitoringu czy w aplikacjach na smartfony.
Jak działa YOLO?
YOLO najpierw dzieli obraz na regularną siatkę (np. 4 × 4 komórki, tak jak na Rysunku 2). Zadaniem każdej komórki w siatce jest wykrycie obiektów, których środek znajduje się w jej obszarze. Dla każdego wykrytego obiektu komórka musi ustalić 3 rzeczy:
- Jakie jest położenie obiektu? W tym celu ustala położenie ramki ograniczającej obiekt (ang. bounding box). Położenie ramki określane jest przy pomocy czterech parametrów: współrzędnych środka ramki (x, y) względem komórki siatki oraz szerokości i wysokości względem całego obrazu.
- Do jakiej klasy należy wykryty obiekt? Typy dostępnych klas muszą być jasno określone (np. samochód, rower, pieszy). Przynależność do każdej klasy jest oceniana osobno.
- Jak bardzo prawdopodobne jest, że w ramce faktycznie znajduje się jakiś obiekt? Wynik podawany jest jako liczba z przedziału 0–1. Od określonej wartości progowej uznajemy, że wykryto obiekt, np. większej niż 0,5.

Przykładowo, jeśli na zdjęciu znajduje się samochód, którego środek wypada w konkretnej komórce siatki, algorytm dla tej komórki powinien: wyznaczyć ramkę obejmującą cały samochód, przypisać wysokie prawdopodobieństwo dla klasy samochód i niskie dla pozostałych klas (np. pieszy czy rower), oraz wskazać wysoką pewność wykrycia obiektu.
Każda komórka może wykryć z góry określoną liczbę obiektów, np. tylko dwa. Może to stanowić problem przy analizie zatłoczonych scen. Ponadto skuteczność detekcji zależy od tego, jak dobrze obiekt wpasowuje się w regularną siatkę, więc obiekty znajdujące się na granicy komórek mogą być trudniejsze do wykrycia.
Nazwa „You Only Look Once” doskonale oddaje główną zaletę tego algorytmu. Każda komórka wykrywa obiekty niezależnie od pozostałych, w związku z tym wszystkie predykcje mogą się odbywać w tym samym czasie. Przekłada się to na jego wyjątkową szybkość działania.
Co się stanie, gdy ten sam obiekt zostanie wykryty przez kilka sąsiadujących komórek siatki? Na przykład, jeśli mamy samochód, którego środek wypada na granicy dwóch komórek? Obie mogą zgłosić jego wykrycie, tworząc niemal identyczne ramki. W celu uniknięcia wielokrotnego wykrywania tych samych obiektów YOLO wykorzystuje technikę zwaną „non-maximum suppression” (eliminacja nie-maksimów, Rysunek 3). Działa ona w ten sposób, że spośród nakładających się ramek wybiera tę najlepszą (o najwyższym współczynniku pewności), a pozostałe usuwa. Aby ustalić, czy ramki faktycznie dotyczą tego samego obiektu, algorytm oblicza dla każdej pary ramek tzw. współczynnik nakładania się (IoU – Intersection over Union). Jest to stosunek pola części wspólnej obu ramek do pola powierzchni ich sumy.

Im wyższy współczynnik IoU (bliższy 1), tym większe prawdopodobieństwo, że ramki opisują ten sam obiekt. Jeśli współczynnik IoU przekracza ustalony próg (np. 0,5), algorytm zachowuje tylko ramkę o wyższym współczynniku pewności.
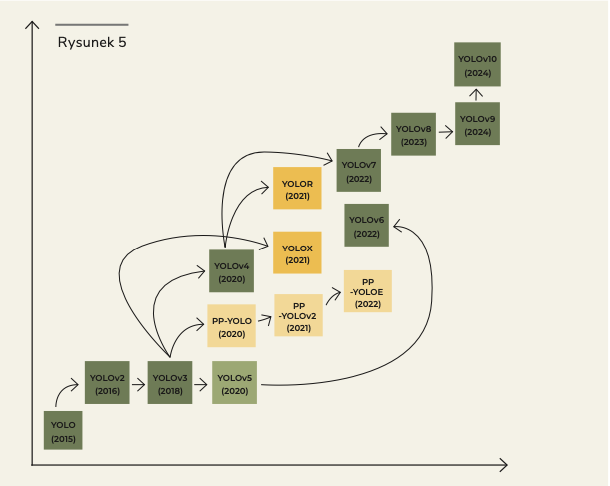
Od pierwszej wersji algorytmu powstało wiele jego udoskonaleń (YOLOv2, YOLOv3, itd.), które zwiększyły dokładność detekcji przy zachowaniu wysokiej szybkości działania. Kolejne wersje wprowadziły między innymi lepsze metody przewidywania ramek ograniczających czy skuteczniejsze strategie wykrywania obiektów o różnych rozmiarach.
YOLO znajduje szerokie zastosowanie w wielu dziedzinach życia i przemysłu (Rysunek 4). Najbardziej znanym przykładem jest analiza ruchu drogowego, podczas której w czasie rzeczywistym analizuje otoczenie pojazdu, wykrywając innych uczestników ruchu, znaki drogowe czy potencjalne przeszkody na drodze. W przemyśle budowlanym YOLO monitoruje bezpieczeństwo pracy. Sprawdza, czy pracownicy stosują się do zasad BHP – noszą wymagane środki ochrony osobistej, takie jak kaski, kamizelki odblaskowe czy szelki bezpieczeństwa. Kolejnym obszarem zastosowań są nowoczesne magazyny i centra logistyczne. Tutaj YOLO wspomaga procesy kontroli jakości i kompletności zamówień, automatycznie sprawdzając zawartość paczek czy palet. System potrafi nie tylko policzyć produkty, ale także zweryfikować ich prawidłowe ułożenie i stan opakowania. Możemy też wykorzystać YOLO w sporcie do analizy ruchu zawodników na boisku i pomiaru statystyk meczowych.

Wszechstronność zastosowań YOLO rodzi jednak poważne pytania etyczne. W lutym 2020 roku Joseph Redmon, twórca algorytmu, ogłosił na Twitterze zaskakującą decyzję o rezygnacji z dalszych badań nad wizją komputerową. Choć wymienione wcześniej przykłady pokazują, jak ta technologia może służyć bezpieczeństwu i efektywności, Redmona niepokoiło jej potencjalne wykorzystanie w celach militarnych oraz wpływ na prywatność obywateli. W kontekście zastosowań wojskowych sama nazwa modelu – „You Only Look Once” – nabiera niepokojącego wydźwięku. Redmon przyznał, że jego wcześniejsze przekonania o nauce znacząco się zmieniły. Dorastając, wierzył, że nauka jest niezależna od poglądów politycznych, a samo prowadzenie badań jest z natury korzystne dla społeczeństwa. Jego decyzja wywołała ważną dyskusję w środowisku naukowym o odpowiedzialności badaczy za sposób wykorzystania ich odkryć.
W tym momencie jednak rozwój YOLO był już nie do zatrzymania i praca nad kolejnymi wersjami YOLO była kontynuowana przez innych naukowców (Rysunek 5). Obecnie najnowszą wersją YOLO jest YOLOv11, która wyszła miesiąc temu.
Jak zacząć pracę z YOLO?
Rozpoczęcie pracy z YOLO jest prostsze, niż mogłoby się wydawać. Najłatwiej jest skorzystać z implementacji dostępnej w ramach biblioteki Ultralytics. Dostępne wersje modeli można wykorzystać na trzy sposoby: używając gotowego modelu wytrenowanego na standardowym zbiorze danych (np. na zbiorze COCO), dostosowując istniejący model do własnych potrzeb poprzez douczenie (tzw. fine-tuning), lub trenując własny model od podstaw na swoim zbiorze danych.
Do przygotowania własnego zbioru danych świetnie sprawdza się narzędzie Label Studio. Jest to darmowa, open-source’owa platforma, która pozwala na sprawne oznaczanie obiektów na zdjęciach. Wystarczy utworzyć projekt, zaimportować zdjęcia i rozpocząć oznaczanie. Dla każdego zdjęcia rysujemy prostokątne ramki wokół interesujących nas obiektów i przypisujemy im odpowiednie etykiety. Label Studio automatycznie zapisuje adnotacje w formacie, który można łatwo przekonwertować do formatu YOLO.

Share
You might be interested in

-
🔒 Modele wizyjne
Modele wizyjne (ang. computer vision models) to gałąź sztucznej inteligencji, która zajmuje się uczeniem maszyn interpretacji i rozumienia świata widzialnego. W najprostszym ujęciu to sztuka przekształcania danych obrazowych w użyteczne informacje i…

-
Co może przydać się studentom?
O wyzwaniach edukacji na kierunkach technicznych i potrzebie dostosowania programów nauczania do realiów współczesnej nauki i rynku pracy rozmawiamy z Barbarą Klaudel, wykładowczynią i specjalistką w dziedzinie sztucznej inteligencji.
