Twój koszyk jest obecnie pusty!
Bielik lokalnie – praktyczne wdrożenie małych modeli językowych
Bielik wylądował! Mały model językowy, który pojawił się na przełomie sierpnia i września 2024 roku, zdobył wysokie noty w testach benchmarków i tym samym uznanie użytkowników.

Pochlebnych opinii nie brakowało. Czy na produkcji też doda nam skrzydeł? Jak uruchomić go całkowicie lokalnie i sprawdzić w zastosowaniach biznesowych? I co to w ogóle są małe modele językowe? Zanim jednak przejdziemy do kodowania, omówimy teorię małych modeli językowych (SLM) i zastanowimy się, dlaczego w niektórych przypadkach „mniej” może oznaczać „więcej”.
Duże modele językowe, takie jak GPT, Gemini PRO czy Claude Sonnet, szybko zyskały popularność w biznesie dzięki prostocie ich integracji – wystarczy kilka linijek kodu i dostęp do płatnego API, by zacząć korzystać z potencjału tych potężnych narzędzi. Jednak w zastosowaniach biznesowych, takich jak analiza korespondencji z klientami, generowanie odpowiedzi na e-maile czy zaawansowane wnioskowanie na podstawie załączników, wykorzystuje się je wciąż nadzwyczaj rzadko. Dlaczego? Zamkniętymi, komercyjnymi modelami trudniej zarządzać – ich wydajność i szybkość mogą się gwałtownie zmieniać, a przetwarzanie danych w chmurze bywa problematyczne lub wręcz niemożliwe, gdy na szali kładziemy ochronę danych wrażliwych, takich jak tajemnica bankowa czy dane medyczne. Remedium na te bolączki okazują się tzw. małe modele językowe (SLM, ang. small language model) – przy czym ich „małość” jest relatywna, bo to wciąż całkiem okazałe modele, posiadające około 10 miliardów parametrów. Choć nie stworzą spójnych i przekonujących dzieł literackich, do zastosowań biznesowych nadają się idealnie: można uruchomić je lokalnie, dostosować do konkretnych potrzeb, kontrolować oraz optymalizować. To modele, które są w pełni naszą własnością, bezpieczne, stabilne. Bielik, model o stricte polskim rodowodzie, właśnie do tej grupy modeli należy.
Uruchomienie modelu lokalnie
Jak można się domyślić, Bielik – podobnie jak inne modele typu SLM – jest dostępny na portalu Hugging Face. Na profilu dostawcy, jakim jest społeczność SpeakLeash, która stworzyła Bielika (https://huggingface.co/speakleash), znajdziemy jednak dziesiątki różnych modeli. Jak wybrać odpowiedni? Do zadań biznesowych najlepiej sprawdzi się model instrukcyjny lub konwersacyjny. W zależności od dostawcy można je znaleźć po słowach kluczowych w nazwie, takich jak „instruct”, lub w tagach, na przykład „conversational”. W przypadku Bielika znajdziemy taki model pod adresem:
https://huggingface.co/speakleash/Bielik-11B-v2.3-Instruct
Czy możemy już zainstalować model?
Jeśli posiadasz kartę GPU z co najmniej 40 GB pamięci vRAM – tak! Bielik ma 11 miliardów parametrów, a jego wagi są dostępne w precyzji 16 bitów, więc do optymalnego działania wymaga zarówno odpowiedniej mocy obliczeniowej GPU, jak i dużej pamięci. Jeśli jednak Twój sprzęt nie spełnia tych wymagań, nie martw się. Dostawcy, w tym także SpeakLeash, udostępniają alternatywne wersje modeli instrukcyjnych zoptymalizowanych pod kątem niższych zasobów, takich jak GGUF, 4-bit, 8FP czy GPTQ.
Są to tzw. modele skwantowane (skompresowane), które charakteryzują się niższą precyzją wag – na przykład 2, 4 lub 8 bitów. Dzięki temu modele te wymagają mniejszych zasobów, takich jak pamięć vRAM i moc obliczeniowa GPU, co czyni je bardziej dostępnymi na sprzęcie o ograniczonych zasobach. Ale nic za darmo – kwantyzacja może wpływać na efektywność i jakość generowanych odpowiedzi.
Jak bardzo? Zgodnie z tzw. prawem Ethana Mollicka najlepszym podejściem jest po prostu regularne testowanie tych modeli, aby określić, które wersje zapewniają najlepszy kompromis między wydajnością a jakością odpowiedzi.
Prawo Ethana Mollicka
„W niektórych zadaniach sztuczna inteligencja jest niezwykle skuteczna, a w innych zupełnie zawodzi lub popełnia drobne błędy. Jeśli jednak nie korzystasz z AI regularnie, trudno będzie ci odróżnić jedne sytuacje od drugich”.
Gdy mamy już wybraną wersję modelu, możemy przystąpić do działania.
Zacznijmy od najprostszej metody – wystarczy, że na stronie modelu, np. https://huggingface.co/speakleash/Bielik-11B-v2.3-Instruct-4bit-ov, klikniesz przycisk „Use this model” po prawej stronie i wybierzesz opcję „Transformers”, a otrzymasz kod do uruchomienia modelu. Przedtem trzeba jednak zainstalować odpowiednie biblioteki, takie jak Transformers, oraz jedną z bibliotek obliczeniowych – PyTorch lub TensorFlow.
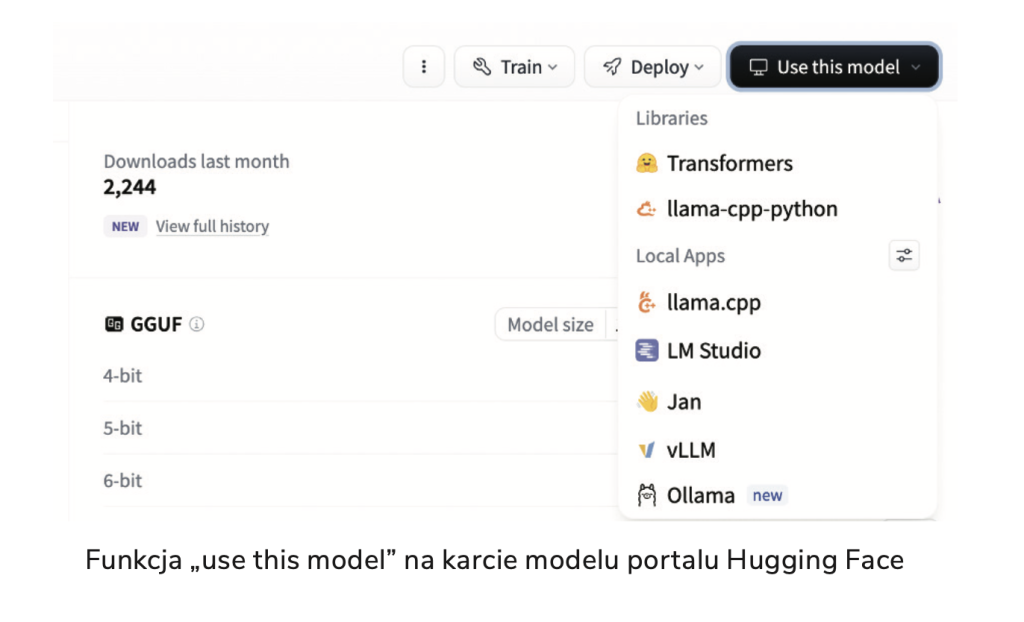
Ta metoda, choć prosta, nie jest jednak optymalna i nie rekomendujemy jej.
Po pierwsze, wymaga pewnego doświadczenia z bibliotekami, takimi jak PyTorch lub TensorFlow, oraz umiejętności ich konfiguracji w zależności od posiadanych zasobów, czyli obecności GPU lub jego braku. Po drugie, kod uruchamiający model trzeba będzie dodać do każdego skryptu lub aplikacji, która z niego korzysta. Po trzecie, metoda ta nie oferuje żadnych opcji optymalizacji ani zarządzania pamięcią. To wszystko są problemy, które ktoś już rozwiązał za nas, ale nie pozwoli nam w te rozwiązania ingerować.
O wiele wygodniej byłoby mieć gotowe API, podobne do tego, które udostępnia OpenAI, i po prostu połączyć się z modelem. Dobra wiadomość: mamy to! Wybieramy ponownie opcję „Use this model” na stronie modelu, a następnie sprawdzamy dostępne integracje – oprócz „Transformers” znajdziemy tam również bardziej zaawansowane pakiety, takie jak vLLM (polecam zostawić na później) oraz Ollama (dla wersji modelu GGUF).
Na początek przygody z lokalną wersją Bielika rekomendujemy właśnie Ollamę. Jeśli dopiero zaczynacie przygodę z pakietem Ollama, najpierw wejdźcie na stronę https://ollama.com/download i zainstalujcie odpowiednie oprogramowanie dla swojego systemu operacyjnego. Następnie macie dwie opcje: możecie wyszukać odpowiedni model bezpośrednio na stronie Ollamy lub wrócić do Hugging Face i tam wybrać opcję „Use this model” przy modelach, które mają w nazwie ciąg „GGUF”.
Zalecamy jednak korzystanie z modeli dostępnych bezpośrednio przez Ollamę – jest ich czasem więcej, ponieważ są także przygotowywane przez niezależnych programistów, a same karty modeli są lepiej opisane i dostosowane do pracy z tym pakietem.
Na stronie ollama.com wyszukujemy model, wpisując frazę „Bielik” – i wybieramy na przykład najnowszą wersję 2.3:
https://ollama.com/SpeakLeash/bielik-11b-v2.3-instruct
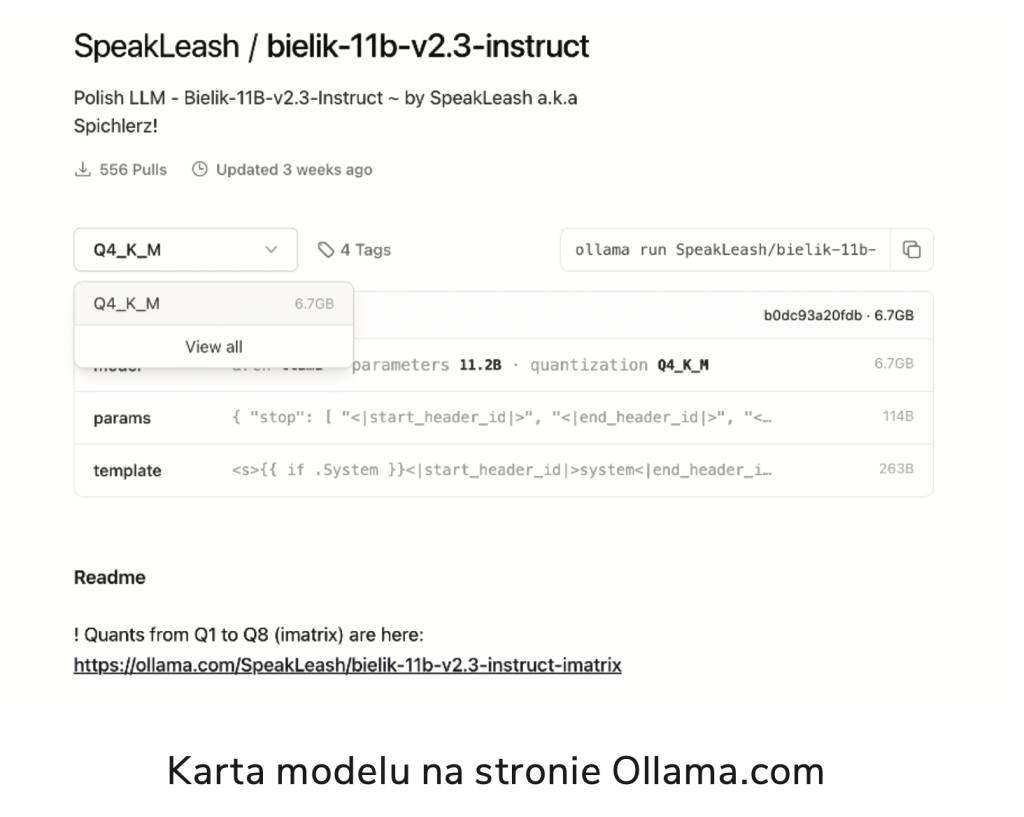
Następnie rozwijamy listę dostępnych modeli i klikamy „View all”. Na dodatkowym ekranie zobaczymy liczbę pobrań modelu, precyzję wag oraz jego rozmiar w GB. Wybieramy pierwszy model do eksperymentów – ja rekomenduję, by zacząć od Q8 i na nim sprawdzić, jak działa na naszym komputerze. Po wyborze wracamy do głównej karty, gdzie wystarczy skopiować komendę „ollama run …”:
ollama run SpeakLeash/bielik-11b-v2.3-instruct:Q8_0
Jeśli macie już zainstalowaną Ollamę, oto komenda do uruchomienia modelu Bielik na Waszym komputerze. Jak łatwo się domyślić, wystarczy zmienić ostatni człon komendy, aby uruchamiać inne modele Bielika, a nawet inne modele dostępne w Ollamie.
Dodatkowo Ollama oferuje wiele innych przydatnych komend, takich jak ps, list czy show, które opisaliśmy w poniższej tabeli.
Popularne komendy aplikacji Ollama
serve – Uruchom Ollamę.
show – Wyświetl informacje o modelu.
run – Uruchom model.
pull – Pobierz model z rejestru.
list – Wyświetl listę dostępnych modeli.
ps – Wyświetl listę uruchomionych modeli.
cp – Skopiuj model.
rm – Usuń model.
Uruchamiamy model za pomocą komendy run, a aplikacja pobierze go i zapisze na komputerze. Dodatkowo Ollamauruchomi w tle serwer, dzięki czemu komputer zacznie oferować API zgodne z protokołem OpenAI. Od tej pory możecie tworzyć skrypty i systemy wykorzystujące lokalnie model Bielik. To oznacza, że możecie przetwarzać nawet najbardziej poufne informacje bez obaw – wszystko będzie przetwarzane wyłącznie lokalnie na Waszym komputerze.
Po uruchomieniu możemy rozpocząć czatowanie z Bielikiem bezpośrednio z terminala. Pamiętajmy jednak, że prawdziwa moc Bielika ujawnia się, gdy połączymy się z nim za pomocą skryptu, przekażemy mu dokumenty do analizy, uprzednio dostosowawszy parametry (np. temperaturę generowania odpowiedzi). Niemniej już teraz możemy poczuć mały przedsmak jego możliwości.
Czas na pierwsze prompty
Bielik ma już uwite gniazdo na naszym dysku. Przed rozpoczęciem kodowania warto sprawdzić kilka komend Ollamy:
- ollama list – aby zobaczyć, jakie modele mamy pobrane,
- ollama ps – aby sprawdzić, które modele są aktywne.
W razie problemów lub po restarcie możemy ponownie uruchomić serwer Ollamy za pomocą komendy ollama serve.
Nasz lokalny serwer Ollamy obsługuje protokół OpenAI, więc wystarczy zainstalować pakiet OpenAI, aby połączyć się z modelem Bielik. Jeśli dodatkowo chcemy porównać wyniki z modelami GPT lub przełączyć skrypt na inny model, również jest to możliwe. Mając skonfigurowane wirtualne środowisko, możemy zainstalować ten pakiet w tradycyjny sposób: pip install OpenAI
I już można przejść do odpytywania modelu. Nasz pierwszy skrypt nie będzie zbyt zaawansowany – poprosimy Bielika o wygenerowanie przykładowego maila biznesowego w określonym stylu, aby sprawdzić, czy wszystko działa poprawnie.
from openai import OpenAI
client = OpenAI(
base_url=’http://localhost:11434/v1′,
api_key=’ollama’,
)
prompt = (
„Wygeneruj treść maila do klienta, który w uprzejmy, dyplomatyczny „
„i przyjazny sposób przypomina o zaległej płatności. Faktura, o której „
„mowa, to nr 01/01/2024 na kwotę 1200 zł netto. Ton maila powinien być „
„kurtuazyjny i wyrozumiały, zachęcający do uregulowania płatności bez „
„wywoływania dyskomfortu.”
)
response = client.chat.completions.create(
model=”SpeakLeash/bielik-11b-v2.3-instruct:Q8_0″,
messages=[
{„role”: „user”, „content”: prompt},
]
)
print(response.choices[0].message.content)
Wystarczy zamienić api_key na klucz uzyskany z naszego konta OpenAI (np. model="gpt-4o"), a także usunąć base_url, aby skrypt korzystał bezpośrednio z modeli OpenAI. Istnieje również możliwość użycia innych modeli, np. z Ollamy, lub połączenia się z innym dostawcą modeli, ponieważ większość z nich obsługuje już protokół OpenAI.
API jest elastyczne, więc można połączyć się z nim za pomocą różnych technologii, takich jak JAVA, JavaScript czy tradycyjny curl.
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama2",
"messages": [
{
"role": "user",
"content": "Cześć!"
}
]
}'
Jeśli wszystko zadziałało i otrzymaliśmy e-mail w oczekiwanym stylu, czas nieco skomplikować skrypt. Po pierwsze, możemy dodać tzw. prompt systemowy, czyli ogólne wytyczne dla modelu. Jest to szczególnie przydatne, gdy tworzymy aplikację, w której użytkownicy korzystają z Bielika i chcemy przekazać zestaw zasad dotyczących stylu lub tonu odpowiedzi, np. „Bądź przyjaznym asystentem, nie odpowiadaj na pytania…”. Dodanie takiego promptu może również pomóc zmniejszyć rozmiar głównego promptu.
Kolejnym krokiem jest dostosowanie parametrów wywołania, takich jak temperatura i maksymalna liczba tokenów. Temperatura (temperature) kontroluje kreatywność modelu, a max_tokens ogranicza długość odpowiedzi, co pozwala lepiej dostosować model do naszych potrzeb.
Oczywiście dostępnych jest więcej parametrów, takich jak top_p, frequency_penalty czy presence_penalty – szczegółowe informacje o ich działaniu można znaleźć w dokumentacji na stronie modelu Bielik.
from openai import OpenAI
client = OpenAI(
base_url=’http://localhost:11434/v1′,
api_key=’ollama’,
)
prompt = (
„Wygeneruj treść maila do klienta, który przypomina o zaległej płatności. „
„Faktura, o której mowa, to nr 01/01/2024 na kwotę 1200 zł netto.\n”
„DANE DŁUŻNIKA:\n”
„Imię i nazwisko: Jan Kowalski\n”
„Adres: ul. Klonowa 1, 00-001 Warszawa\n”
„NIP: 123-456-78-90\n”
„Telefon: 123-456-789\n”
„DANE WIERZYCIELA:\n”
„Firma: Firma XYZ\n”
„Adres: ul. Dębowa 2, 00-002 Warszawa\n”
„NIP: 987-654-32-10\n”
„Telefon: 987-654-321\n”
)
system_prompt = (
„Bądź bardzo uprzejmy i wyrozumiały, ale jednocześnie stanowczy. „
„Jednak zawsze profesjonalny i kurtuazyjny.”
)
response = client.chat.completions.create(
model=”SpeakLeash/bielik-11b-v2.3-instruct:Q8_0″,
messages=[
{„role”: „system”, „content”: system_prompt},
{„role”: „user”, „content”: prompt},
],
temperature=0.4,
max_tokens=1000,
)
print(response.choices[0].message.content)
Ponieważ Bielik działa w środowisku lokalnym, możemy bez obaw dodać dane adresowe klienta. Dodatkowo zwiększyłem wartość parametru temperatura, aby e-mail był bardziej zróżnicowany i miał nieco swobodniejszy ton.
Oczywiście użyty prompt jest tylko przykładowy. Gdybyśmy chcieli stworzyć rzeczywistego asystenta do windykacji, warto byłoby przekazać pełny zestaw wytycznych dotyczących tonu e-maili, zależnie na przykład od liczby ponagleń. Dobrze byłoby także dołączyć dodatkowe informacje, takie jak numer konta, odsetki, szczegóły dotyczące usługi i inne istotne dane.
Bielik, nasz SLM, świetnie radzi sobie z analizą i strukturyzacją tekstów, więc zobaczmy, jak może to wyglądać w praktyce. Wyobraźmy sobie przykładową opinię z internetu (pisownia oryginalna):
No więc, lokata w tym banku spoko, wszystko szybko załatwione, ale mogliby dać lepsze oprocentowanie, bo teraz to trochę lipa. Z kontem bywa różnie, czasem jakieś dziwne opłaty wyskakują i człowiek się zastanawia, skąd to się bierze. Mogliby to jakoś prościej ogarnąć, żeby człowiek nie musiał się głowić.
A aplikacja? No, tu jest dobrze, bo wszystko można załatwić z telefonu, ale czasem się przywiesza. I serio, przydałby się dark mode, bo po nocy to oczy wypala. Ale za to chat z pracownikiem to sztos – wszystko w 5 sekund załatwione, jakby człowiek gadał z kumplem. Ogólnie bank okej, ale mogliby parę rzeczy poprawić, żeby było jeszcze lepiej.
Elo! Wroclaw Lover
Analiza wydźwięku (ang. sentiment)? Tak, ale z Bielikiem (i ogólnie z SLM-ami) może wyglądać to zupełnie inaczej. Po pierwsze, przed analizą możemy podzielić opinię na wątki, produkty czy segmenty, ponieważ klient może pochwalić jedną część usługi, a inną skrytykować. Po drugie, Bielik dobrze radzi sobie z wykrywaniem sarkazmu, ironii, literówek i języka potocznego, co czyni go odpornym na wypowiedzi niejednoznaczne. Po trzecie, Bielik nie jest rozliczany per zużyty token – możemy przetwarzać setki tysięcy komentarzy i opinii bez ograniczeń.
Dodatkowo można pokusić się o analizę „między wierszami”, np. pseudonim „Wroclaw Lover” może sugerować, że mamy do czynienia z klientem z Wrocławia.
Kod to jedno, ale równie ważne jest przygotowanie odpowiedniego promptu:
Przeanalizuj dokładnie opinię o produkcie bankowym, aby zidentyfikować wszystkie opinie oraz pomysły na temat produktów lub usług bankowych. Sklasyfikuj je jako pozytywne, negatywne lub neutralne oraz określ, czy jest to opinia, czy pomysł na usprawnienie. Każdy element opinii powinien mieć fragment maila oraz skorygowaną wersję merytoryczną, pozbawioną języka potocznego.
Zidentyfikuj również wszystkie dostępne cechy klienta, takie jak płeć, miejsce zamieszkania, wiek, wykształcenie itp., na podstawie pośrednich i bezpośrednich informacji w tekście.
W skrócie, chcemy, aby Bielik wyekstrahował wszelkie opinie, pomysły i sugestie, a następnie odpowiednio je sklasyfikował. Kolejnym krokiem jest stworzenie wersji merytorycznej, pozbawionej języka potocznego. Na koniec niech spróbuje wyciągnąć jakiekolwiek dodatkowe informacje o autorze. Temperaturę ustawiliśmy na 0,0, aby uzyskać maksymalnie spójne wyniki.
from openai import OpenAI
client = OpenAI(
base_url=’http://localhost:11434/v1′,
api_key=’ollama’,
)
prompt = (
„Przeanalizuj dokładnie opinię o produkcie bankowym, aby zidentyfikować wszystkie opinie oraz „
„pomysły na temat produktów lub usług bankowych. Sklasyfikuj je jako pozytywne, negatywne lub neutralne „
„oraz określ, czy jest to opinia, czy pomysł na usprawnienie. Każdy element opinii powinien mieć fragment maila „
„oraz skorygowaną wersję merytoryczną bez języka potocznego. Zidentyfikuj również wszystkie dostępne cechy klienta, „
„takie jak płeć, miejsce zamieszkania, wiek, wykształcenie itp., na podstawie pośrednich i bezpośrednich informacji w tekście.”
)
text = (
„OPINIA Z INTERNETU:\n”
„No wiec, lokata w tym banku spoko, wszystko szybko zalatwione, ale mogliby dac lepsze oprocentowanie, bo teraz „
„to troche lipa. Z kontem bywa roznie czasem jakies dziwne oplaty wyskakuja i czlowiek sie zastanawia, skad to sie bierze. „
„Mogliby to jakos prosciej ogarnac, zeby czlowiek nie musial sie glowic. A aplikacja? No, tu jest dobrze, bo wszystko mozna „
„zalatwic z telefonu, ale czasem sie przywiesza. I serio, przydalby sie dark mode, bo po nocy to oczy wypala. Ale za to chat „
„z pracownikiem to sztos wszystko w 5 sekund zalatwione, jakby czlowiek gadal z kumplem. Ogolnie bank okej ale mogliby pare „
„rzeczy poprawic zeby bylo jeszcze lepiej.\nElo! Wroclaw Lover”
)
response = client.chat.completions.create(
model=”SpeakLeash/bielik-11b-v2.3-instruct:Q8_0″,
messages=[
{„role”: „user”, „content”: prompt + „\n” + text}
],
temperature=0.0,
max_tokens=1000,
)
print(response.choices[0].message.content)
Wynik w formacie JSON, proszę
Wynik jest świetny (przynajmniej pod względem merytorycznym). Jednak dalsza analiza, zapisywanie w bazie danych czy eksport do Excela może nastręczać trudności w przypadku danych tekstowych.
**Opinie:**
1. Pozytywna: „lokata w tym banku spoko, wszystko
szybko zalatwione”
– Skorygowana wersja: Lokata w tym banku jest
wygodna i proces jej otwarcia przebiega sprawnie.
2. Negatywna: „mogliby dac lepsze oprocentowanie,
bo teraz to troche lipa”
– Skorygowana wersja: Oprocentowanie lokaty
mogłoby być korzystniejsze, ponieważ obecne warunki
nie są zadowalające.
3. Negatywna: „czasem jakies dziwne oplaty wyskaku-
ja i czlowiek sie zastanawia, skad to sie bierze”
– Skorygowana wersja: Czasami pojawiają się
nieoczekiwane opłaty, co powoduje konsternację
klienta.
4. Pomysł na usprawnienie: „mogliby to jakos pro-
sciej ogarnac, zeby czlowiek nie musial sie glowic”
– Skorygowana wersja: Bank powinien uprościć
system opłat i oprocentowania, aby klient mógł
łatwiej zrozumieć swoje koszty i korzyści.
5. Pozytywna: „aplikacja? No, tu jest dobrze,
bo wszystko mozna zalatwic z telefonu”
– Skorygowana wersja: Aplikacja mobilna banku
jest wygodnym narzędziem do zarządzania finansami.
6. Negatywna: „ale czasem sie przywiesza”
– Skorygowana wersja: Aplikacja czasami
działa nieprawidłowo, co powoduje problemy
z jej używaniem.
7. Pomysł na usprawnienie: „przydalby sie dark
mode, bo po nocy to oczy wypala”
– Skorygowana wersja: Wprowadzenie trybu
ciemnego (dark mode) byłoby korzystne dla
użytkowników korzystających z aplikacji w nocy.
8. Pozytywna: „chat z pracownikiem to sztos
wszystko w 5 sekund zalatwione, jakby czlowiek
gadal z kumplem”
– Skorygowana wersja: Czat z pracownikiem banku
jest bardzo efektywny i przyjazny, co sprawia,
że komunikacja przebiega szybko i bezproblemowo.
9. Neutralna: „Ogolnie bank okej ale mogliby pare
rzeczy poprawic zeby bylo jeszcze lepiej”
– Skorygowana wersja: Bank jest ogólnie dobry,
ale istnieje potencjał do wprowadzenia kilku
ulepszeń, aby usługi były jeszcze bardziej satys-
fakcjonujące.
**Cechy Klienta:**
– Płeć: nieokreślona (używane są formy neutralne)
– Miejsce zamieszkania: Wrocław (Wroclaw Lover)
– Wiek: nieokreślony
– Wykształcenie: nieokreślon
bSpróbujmy więc poprosić o wynik w formacie JSON – dzięki temu łatwiej będzie zaimportować dane do Excela, innego modelu czy bazy danych. SLM świetnie radzą sobie z takimi strukturami, jednak warto dokładnie zdefiniować ich formalny układ. Polecam użycie tzw. JSON Schema (https://json-schema.org/) – formalnego opisu obiektów, w którym można określić atrybuty, wskazywać, które z nich są wymagane lub opcjonalne, oraz zdefiniować typy danych i inne przydatne właściwości pożądanej struktury.
Oto przykładowa struktura JSON:
{
„feedback”: [
{
„original_text”: „obsługa spoko!”,
„feedback_item”: „klient chwali obsługę klienta”,
„type”: „opinion”,
„sentiment”: „pozytywny”
},
{
„original_text”: „zrobcie dark mode Misie”,
„feedback_item”: „dodać dark mode do aplikacji”,
„type”: „ideas”
}
],
„person”: [
{
„feature”: „miasto zamieszkania”,
„value”: „Warszawa”
}
]
}
Wówczas JSON Schema wyglądałby następująco:
{
„$schema”: „http://json-schema.org/draft-07/schema#”,
„type”: „object”,
„properties”: {
„feedback”: {
„type”: „array”,
„items”: {
„type”: „object”,
„properties”: {
„original_text”: {
„type”: „string”
},
„feedback_item”: {
„type”: „string”
},
„type”: {
„type”: „string”,
„enum”: [„opinion”, „ideas”]
},
„sentiment”: {
„type”: „string”
}
},
„required”: [„original_text”, „feedback_item”, „type”]
}
},
„person”: {
„type”: „array”,
„items”: {
„type”: „object”,
„properties”: {
„feature”: {
„type”: „string”
},
„value”: {
„type”: „string”
}
},
„required”: [„feature”, „value”]
}
}
},
„required”: [„feedback”]
}
Warto dodać zarówno schemat, przykładowy wynik, jak i prostą listę kluczy bezpośrednio do promptu, co ułatwi modelowi generowanie danych w odpowiedniej formie (na czerwono zmiany w prompcie):
Przeanalizuj dokładnie opinię o produkcie bankowym, aby zidentyfikować wszystkie opinie oraz pomysły na temat produktów lub usług bankowych. Sklasyfikuj je jako pozytywne, negatywne lub neutralne oraz określ, czy jest to opinia, czy pomysł na usprawnienie. Każdy element opinii powinien mieć fragment maila (original_text) oraz skorygowaną wersję merytoryczną, pozbawioną języka potocznego (feedback_item). Zidentyfikuj również wszystkie dostępne cechy klienta, takie jak płeć, miejsce zamieszkania, wiek, wykształcenie itp., na podstawie pośrednich i bezpośrednich informacji w tekście. Wynik przedstaw jako obiekt JSON z kluczami: feedback oraz person.

Teraz wynik można analizować, zapisywać, zliczać – do woli, w zależności od potrzeb!
{
„$schema”: „http://json-schema.org/draft-07/schema#”,
„type”: „object”,
„properties”: {
„feedback”: {
„type”: „array”,
„items”: {
„type”: „object”,
„properties”: {
„original_text”: {
„type”: „string”
},
„feedback_item”: {
„type”: „string”
},
„type”: {
„type”: „string”,
„enum”: [„opinion”, „ideas”]
},
„sentiment”: {
„type”: „string”
}
},
„required”: [„original_text”, „feedback_item”, „type”]
}
},
„person”: {
„type”: „array”,
„items”: {
„type”: „object”,
„properties”: {
„feature”: {
„type”: „string”
},
„value”: {
„type”: „string”
}
},
„required”: [„feature”, „value”]
}
}
},
„required”: [„feedback”]
}
Jak widać, Ollama i Bielik to wymarzony duet, a wersje skwantyfikowane radzą sobie doskonale zarówno z zaawansowaną analizą tekstu, jak i generowaniem wyników w wygodnym formacie JSON. Co więcej, istnieje możliwość pobrania innych modeli SLM i lokalnego stworzenia ich „mieszanki”, czyli tzw. Mixture of Agents.
Do wersji produkcyjnej Bielika rekomendujemy jednak precyzję FP16 oraz wdrożenie w odpowiednio skonfigurowanym środowisku, np. w konteneryzowanej wersji vLLM. Chociaż… może są jeszcze inne, lepsze, prostsze, wydajniejsze konfiguracje? Zachęcamy do eksperymentów! A potem każdym spektakularnym sukcesem, ale też ewentualnym potknięciem modelu, możecie podzielić się ze SpeakLeash, prawowitym zaklinaczem gatunku cyfrowych Bielików.
Tymczasem życzę wysokich lotów!

Podziel się
Może Cię zainteresować

🔒 Guardrails. Naprawdę przednia straż
W systemach sztucznej inteligencji guardrails pełnią funkcję strażników, którzy kontrolują jej działanie, zapewniając bezpieczeństwo, zgodność z regulacjami i unikanie szkodliwych treści. To tak naprawdę jednocześnie straż przednia i tylna, bo filtruje dane…

-
🔒 Graf wiedzy i AI: synergiczna współpraca w biznesie
Grafy wiedzy mają swoje korzenie w teorii grafów, jednym z działów matematyki o całkiem solidnej historii. Jedna z prac, która dała początek teorii grafów, opisywała słynne zagadnienie mostów królewieckich.

-
🔒 RAG na sterydach czyli generowanie treści z turbodoładowaniem
Zaprezentowana już w 2020 roku przez firmę Meta, technologia ta zapoczątkowała rozwój licznych chatbotów, asystentów oraz systemów QA (ang. question answering, systemy pytań i odpowiedzi) służących do zarządzania wiedzą. Jak działa, i…
