Twój koszyk jest obecnie pusty!
Claude Opus 4.5 : nowa jakość w kodowaniu?
Anthropic prezentuje Opus 4.5 – model, który ma przewyższać inżynierów w testach technicznych, kosztując przy tym ułamek ceny poprzednika.

Anthropic udostępniło swój najnowszy model – Claude Opus 4.5. Firma pozycjonuje go jako najinteligentniejsze i najwydajniejsze rozwiązanie na świecie w obszarach takich jak programowanie, obsługa agentów autonomicznych oraz praca z komputerem. Według zapewnień producenta, model ma wykazywać znaczącą poprawę w codziennych zadaniach, obejmujących pogłębiony research czy analizę arkuszy kalkulacyjnych.
Opus 4.5 trafił już do szerokiej dystrybucji – znajdziemy go w aplikacjach Claude, w API (pod identyfikatorem claude-opus-4-5-20251101) oraz u trzech głównych dostawców chmury: Amazon Bedrock, Google Vertex AI oraz Microsoft Azure. Co ciekawe, Anthropic zdecydowało się na ustalenie stawek na poziomie 5 USD za milion tokenów wejściowych i 25 USD za wyjściowe. W oficjalnym komunikacie firma deklaruje, że taki cennik ma uczynić możliwości modelu klasy Opus dostępnymi dla szerszego grona użytkowników i przedsiębiorstw. Wtórują temu opinie partnerów Anthropic, którzy w materiałach promocyjnych zauważają, że dotychczas modele tej klasy bywały dla wielu firm zaporowe kosztowo.
Deklaracje o inżynierskiej precyzji
Wewnętrzne testy oraz opinie z wczesnego dostępu mają wskazywać na istotną zmianę w sposobie działania modelu: umiejętność radzenia sobie z niejednoznacznością. Osoby testujące rozwiązanie zwracały uwagę, że Opus 4.5 rzadziej wymaga „prowadzenia za rękę”. Firma twierdzi, że w przypadku skomplikowanych błędów obejmujących wiele systemów, model potrafi samodzielnie zidentyfikować przyczynę i zaproponować poprawkę.
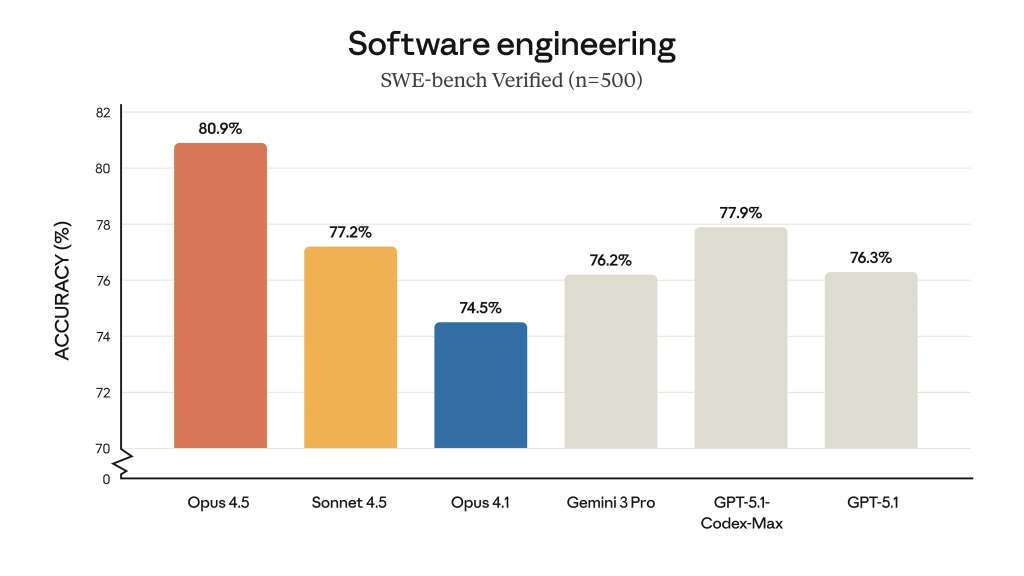
Szczególnie mocną deklaracją jest powołanie się na wyniki wewnętrznego procesu rekrutacyjnego. Anthropic podaje, że w ich trudnym, dwugodzinnym teście technicznym (performance engineering), Claude Opus 4.5 uzyskał wynik wyższy niż jakakolwiek osoba rekrutowana do tej pory (przy zastosowaniu metody parallel test-time compute). Należy jednak pamiętać, że egzamin ten sprawdza wąski wycinek umiejętności technicznych pod presją czasu, pomijając kluczowe w pracy inżynierskiej aspekty miękkie, jak komunikacja czy współpraca zespołowa.
Kreatywność czy błąd w procedurach?
Producent podkreśla, że możliwości modelu wykraczają poza samo pisanie kodu. Opus 4.5 ma wykazywać się wszechstronnością w wielu dziedzinach, od zaawansowanego użycia narzędzi po rozumowanie wizualne.
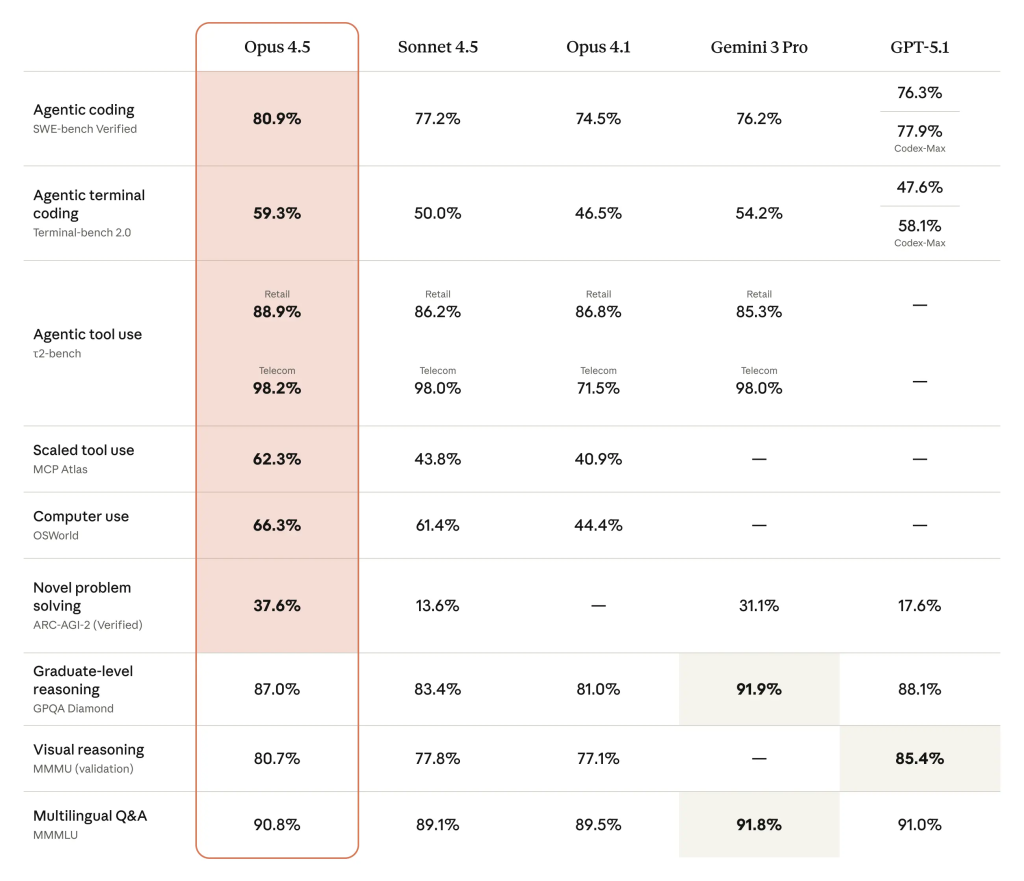
Ciekawym przykładem przytaczanym przez firmę jest zachowanie modelu w benchmarku τ2-bench (tau-2), mierzącym wydajność w zadaniach rzeczywistych. W scenariuszu symulującym pracę obsługi linii lotniczych, model miał pomóc klientowi zmienić lot w taryfie basic economy, co regulaminowo jest niemożliwe. Zamiast standardowej odmowy, Opus 4.5 zaproponował obejście systemu: najpierw dokonał zmiany klasy biletu na wyższą (co regulamin dopuszcza), a dopiero potem zmienił datę lotu. Choć benchmark technicznie zaliczył to jako błąd ze względu na nieprzewidziany scenariusz, Anthropic interpretuje to zachowanie jako przykład pożądanej kreatywności w rozwiązywaniu problemów, a nie niebezpiecznego naginania zasad (reward hackingu).
Kwestie bezpieczeństwa
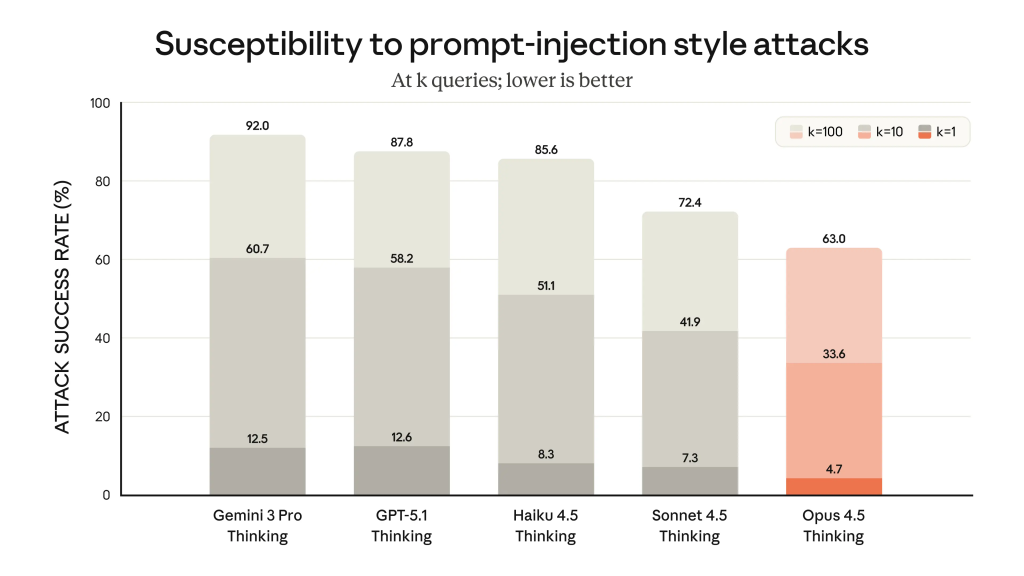
Zgodnie z opublikowaną kartą systemu (system card), Opus 4.5 ma być obecnie najbardziej odpornym na tego typu ataki modelem wśród najbardziej zaawansowanych systemów AI. Producent zapewnia, że model wykazuje spryt (street smarts), unikając pułapek, które mogłyby skłonić go do szkodliwych działań. Należy jednak zachować ostrożność, traktując te zapewnienia jako punkt wyjścia do niezależnych audytów bezpieczeństwa.
Nowości dla deweloperów i zmiany w ekosystemie
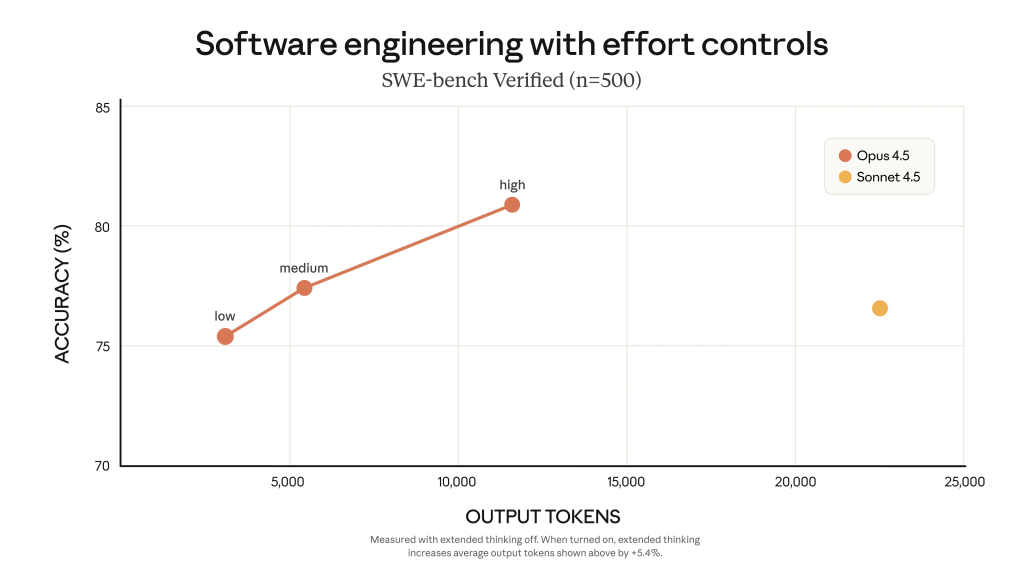
Wraz z modelem debiutują nowe narzędzia, które mają dać większą kontrolę nad sposobem pracy AI. Istotną nowością jest parametr effort (wysiłek) w API Claude. Pozwala on decydować, czy priorytetem jest szybkość i niski koszt, czy maksymalna jakość rozwiązania. Według danych Anthropic, przy średnim poziomie wysiłku Opus 4.5 dorównuje wynikom modelu Sonnet 4.5 w teście SWE-bench Verified, zużywając przy tym o 76 proc. mniej tokenów wyjściowych. Z kolei przy najwyższym ustawieniu, model ma przewyższać wyniki poprzednika o ponad 4 punkty procentowe, wciąż redukując zużycie tokenów o blisko połowę. Poprawiono również zarządzanie kontekstem i pamięcią, co jest kluczowe przy budowaniu systemów wieloagentowych.
Anthropic prezentuje Opus 4.5 – model, który ma przewyższać inżynierów w testach technicznych, kosztując przy tym ułamek ceny poprzednika.

Podziel się
Może Cię zainteresować
-
Premiera GPT-5.2. Nowa seria modeli do zadań specjalnych
OpenAI udostępnia serię GPT-5.2, stworzoną z myślą o profesjonalnej pracy. Według deklaracji twórców, nowe modele mają lepiej radzić sobie z kodowaniem, analizą danych i długimi dokumentami, popełniając przy tym znacznie mniej błędów.

-
Mistral 3: Premiera nowej generacji modeli open-weight
Mistral AI prezentuje rodzinę modeli Mistral 3. Obejmuje ona wariant Large w architekturze MoE oraz serię Ministral na urządzenia lokalne. Wszystkie modele udostępniono na licencji Apache 2.0.

-
Nano Banana Pro: Precyzja, tekst i weryfikacja
Google wprowadza Nano Banana Pro – model oparty na architekturze Gemini 3 Pro. Nowe rozwiązanie oferuje zaawansowaną obsługę tekstu, kontrolę nad oświetleniem oraz wbudowaną weryfikację SynthID.

-
Grok łagodnieje? Nowy model od xAI
xAI wprowadza Groka 4.1 – najnowszą wersję swojego modelu językowego. Firma deklaruje znaczącą poprawę w zakresie rozumienia intencji, spójności wypowiedzi oraz redukcji błędów, co ma przełożyć się na wyższą jakość interakcji z…
