Twój koszyk jest obecnie pusty!
Transformer – jak działa rewolucyjna architektura?
Na co warto zwrócić w tego typu modelach uwagę, i dlaczego przede wszystkim na mechanizm uwagi?

Ten artykuł jest częścią serii „Tłumaczymy! Naukowe klasyki”, do której zapraszamy ekspertów, by dla nas objaśniali najważniejsze, klasyczne już, publikacje naukowe z dziedziny sztucznej inteligencji.
Nie wiem, jak to świadczy o moim życiu prywatnym, ale gdyby ktoś zapytał mnie o trzy najbardziej sexy słowa roku 2023, to byłyby to: generatywny, pretrenowany i transformer, które razem składają się na GPT, jak w ChatGPT. (ang. Generative Pretrained Transformer, GPT). GPT gościł na wielkich salach konferencyjnych i w małych gabinetach, najpierw naukowych, potem biznesowych, a na końcu zawitał w naszych salonach i kuchni. O GPT rozmawiano, GPT używano, ale nie dla wszystkich jasne było, czym ten twór właściwie jest? Sięgnijmy zatem do źródeł i przyjrzyjmy się, jak działa ta rewolucyjna architektura.
Słowo „generatywny” jest zrozumiałe i z grubsza oznacza, że produkujemy coś nowego. „Pretrenowany” może już nie jest tak intuicyjny, ale upraszczając, można to opisać jako coś, co widziało i uczyło się z dużego zbioru różnorakich danych. I tu dochodzimy do niełatwej ściany – a co z transformerem? Czym jest tajemniczy twór, który podbił biznesowe salony? Niezależnie od tego, czy masz programi- styczne doświadczenie, czy ciekawość nowicjusza, po tej lekturze transformer nie będzie Ci obcy!
Transformer to sieć neuronowa (wyobraź sobie kawałek mózgu do wykonywania określonych zadań, ale w komputerze), która po raz pierwszy została zaproponowana przez naukowców z Google’a w publikacji Attention is All You Need.
Pierwotnym zadaniem transformera było tłumaczenie tekstu z jednego języka na drugi (trochę dosłownie transformowanie, czyli przekształcanie jednego w drugie). Szybko jednak zauważono, że można zastosować tę samą formułę do przetwarzania słów w obrębie tego samego języka, aby generować zupełnie nowe teksty.
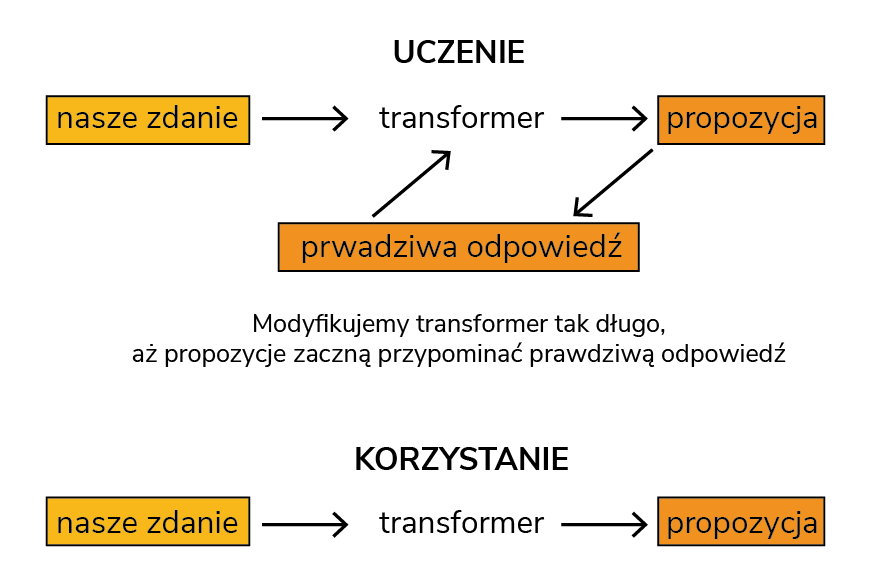
Żeby dobrze zrozumieć co i kiedy transformer robi, musimy rozbić to na 2 kroki typowe dla dowolnej sieci neuronowej: proces uczenia i proces korzystania (pokazane na rysunku 1). Korzystanie jest łatwe – wkładamy nasze zdanie do nauczonego transformera (np. „Ala ma…”), a transformer mówi nam co według niego jest najlepszym dopełnieniem (np. „…kota”). Mając takie dopełnienie, możemy odpytać transformer jeszcze raz („Ala ma kota”) i zobaczyć, co nam zaproponuje tym razem, jakie będzie następne najbardziej prawdopodobne według niego słowo („Ala ma kota i…”). Jak widzisz, powtarzając tę operację, możemy dojść do bardzo długiego tekstu i dowiedzieć się, jakie jeszcze zwierzęta ma Ala, co z nimi robi i co z tego wynika.
W procesie uczenia dysponujemy dużą ilością danych, które, dla uproszczenia, składają się z par: zdanie („Ala ma…”) i odpowiedź („…kota”) albo „Jaś ma kota i…” oraz „psa”. Okazuje się, że w takich danych, jak i w samym języku, niektóre kombinacje są bardziej prawdopodobne niż inne. Co to znaczy?
Wyobraź sobie, że idziemy ulicą i prosimy przechodniów o dokończenie zdania „Ala ma…”. Na 100 zapytanych osób 90 odpowie nam „kota”, 5 przekornie odpowie „psa”, a kolejne 5 powie „daj mi spokój, spieszę się do pracy”. Te proporcje w naszych zebranych danych (kot: 90/100, pies: 5/100 etc.) będą nam opisywać, jak prawdopodobne jest dopełnienie („kota”), mając kontekst naszego zdania („Ala ma…”). A dlaczego się wszyscy upierają przy kocie? Bo nasz wewnętrzny ludzki „transformer” też kiedyś został tego nauczony – w szkole.
Wracając do dużej ilości danych. W takich danych również występują proporcje i to właśnie ich chcemy nauczyć nasz transformer. Aby to zrobić, będziemy wkładać w transformer zdania tak długo, aż nauczy się generować propozycje przypominające te faktyczne, najbardziej prawdopodobne dopełnienia. Na początku będzie on strzelał na ślepo i rzucał losowe odpowiedzi, ale z czasem i sporą ilością danych może zacząć mówić z sensem, odzwierciedlając to, co mówią nasi typowi przechodnie na ulicy.
I tu muszę się do czegoś przyznać – proces, który opisałam, mógłby zostać przypisany jeszcze wielu innym sieciom neuronowym, nie tylko transformerowi. Co w takim razie czyni transformer transformerem? Niuansów jest wiele, ale gdybym musiała wybrać te moim zdaniem najważniejsze, byłby to wspomniany już mechanizm uwagi (ang. attention) oraz wielowar- stwowy perceptron (ang. multi-layer perceptron, MLP). Spokojnie, już tłumaczę, o co chodzi!
Wcześniej napisałam, że do transformera wkładamy nasz kontekst, czyli zdanie („Ala ma…”). Niestety, dla komputera nic to nie oznacza, więc musimy przetłumaczyć to na jedyny zrozumiały dla niego język – liczby. Upraszczając, każde słowo kodowane jest za pomocą zestawu liczb nazywanego wektorem, który ma reprezentować to słowo i jego pozycję w całym zdaniu lub kontekście. Jeśli pamiętasz ze szkoły układ współrzędnych, możesz to rozumieć graficznie tak jak na rysunku 2.
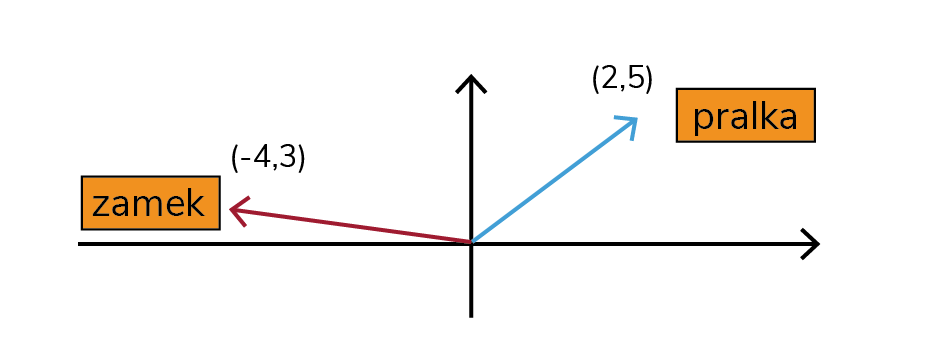
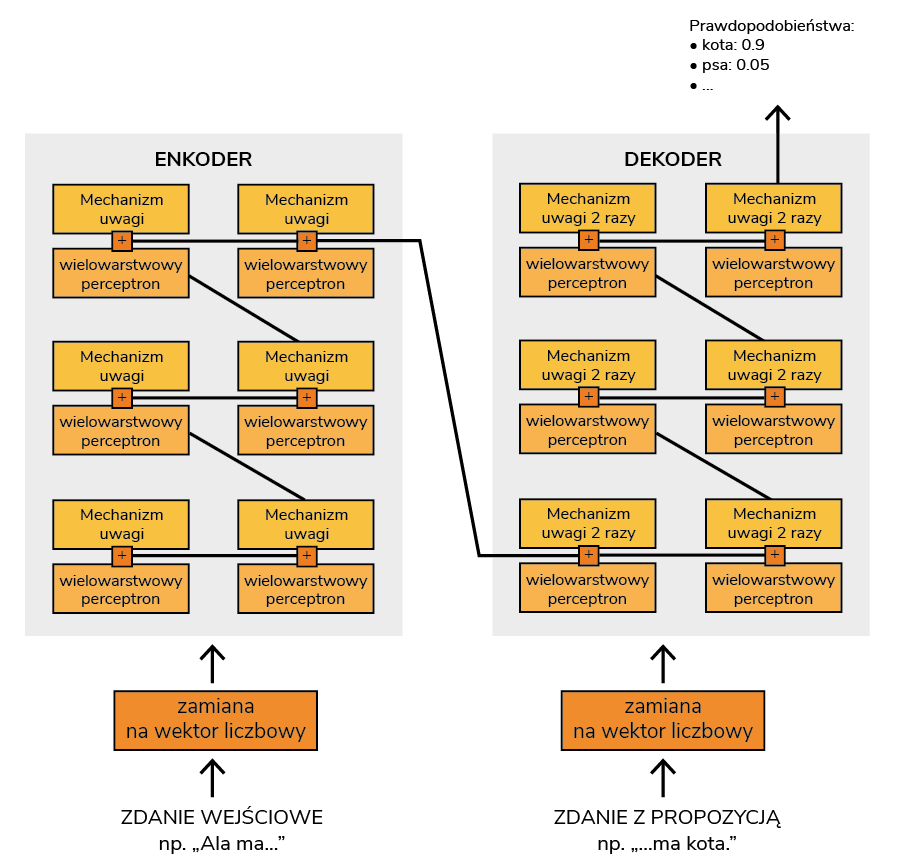
Takie wektory przechodzą dalej do mechanizmu uwagi. Po co? W samym wektorze zawarta jest jedynie informacja o słowie, a nie całym kontekście, a przecież kontekst ma bardzo duże znaczenie! To właśnie kontekst będzie wyznaczać, czy zamek jest miejscem, w którym żyje królowa, czy zapięciem bluzy. Mechanizm uwagi pozwala nam zatem powiązać ze sobą wektory i zaktualizować je tak, aby wzbogacić je o istotny kontekst (rysunek 3). Dzięki temu wiemy też, na które informacje warto zwrócić uwagę, bo będą kluczowe w przewidywaniu kolejnego słowa, a które możemy zignorować.

W następnym kroku nasze wzbogacone wektory wpadają do wielowarstwowego perceptrona, który jest stosowaną już od lat siecią neuronową. Jego działanie można wyjaśnić łatwo przez pryzmat gotowania. Żeby przygotować pyszny sernik, potrzeba odpowiednich proporcji twarogu, czasem białej czekolady i innych składników, do tego odpo- wiednio długo je ucierać i piec. Tylko jedna kombinacja tych wszystkich elementów da Ci dokładnie ten sam smak – Ty znasz ten konkretny przepis, ale ktoś inny może go nie znać i próbować uzyskać taki sam sernik metodą prób i błędów. W perceptronie również mamy miliony, a nawet miliardy takich elementów, ustawionych w zły i dobry sposób i mówiących nam, które fragmenty wektorów są ważne i trzeba je uwypuklić, a które nie (np. możemy piec o kilka minut dłużej lub krócej, ale jak dodamy za dużo jajek, to się nie uda).
Dla pewności zatrzymajmy się na chwilę przy mechanizmie uwagi (tym bardziej jeśli zgodnie z tytułem „trzeba nam tylko uwagi”).
Mechanizm uwagi w trzech krokach
Co mamy na myśli, gdy słyszymy słowo „zamek”? To zależy, prawda? A dokładniej od kontekstu, tego, co usłyszeliśmy chwilę wcześniej, gdzie się znajdujemy, co widzimy przed sobą etc. Dzięki mechanizmowi uwagi transformer robi podobną rzecz – choć początkowo ma pewne wyobrażenie słowa „zamek”, może je aktualizować, dostając dodatkowy kontekst (np. „Król mieszkał w pięknym zamku”). Taki kontekst znaczeniowy jest dla transformera ważny, aby poprawnie przewidywać kolejne słowo w zadanej przez nas sekwencji – bo przecież lepiej brzmi „Król mieszkał w pięknym zamku na wzgórzu” niż „Król mieszkał w pięknym zamku od spodni”. Na poniższym przykładzie widać z kolei, jak kontekst zmienia się dla kolejnych słów i zdań. By odgadnąć nazwisko Mickiewicza, istotne były: tytuł dzieła, informacja o epoce oraz słowo „pisarz”. W kolejnym zdaniu natomiast, by sprecyzować, o jakiego Adama chodzi, ważne było uwzględnienie, że przed chwilą padło nazwisko „Mickiewicz” i tak dalej.

I to tyle! Czy mój opis wyczerpuje temat trans- formera? Oczywiście, że nie, ale chciałam rozłożyć go na czynniki pierwsze i wyciągnąć esencję. Esencję, która właśnie pozwoliła Ci być o krok dalej od wielu entuzjastów AI i zrozumieć, co w transformerze piszczy. Mając taką podstawę, będziesz gotowy na analizę tego, jak działają duże modele generatywne – które wychodzą od transformera, ale rozszerzają go m.in. o aspekt konwersacji, a nawet wychowania modelu (ang. alignment).
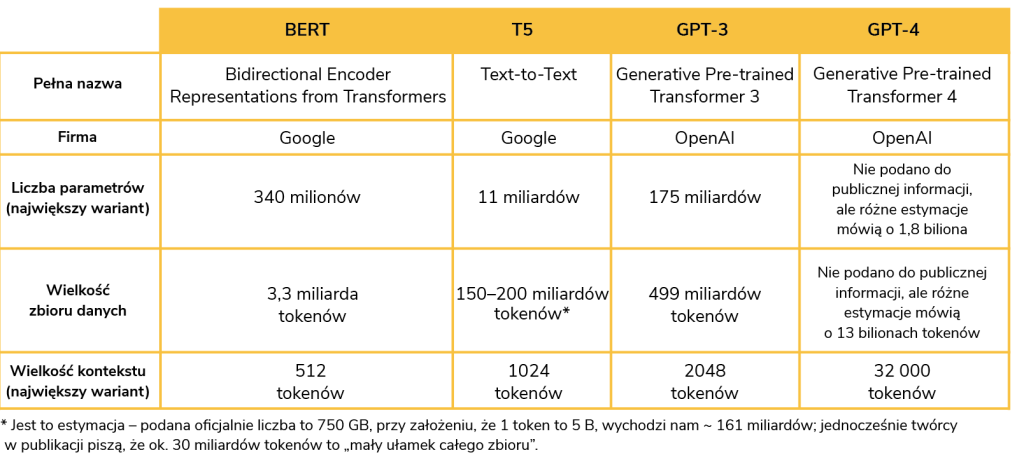
Dla ciekawskich: porównaj popularne transformery!

Share
You might be interested in
-
🔒 Autorzy technologii deepfake – najwięksi złoczyńcy XXI wieku?
Jakiś czas temu miałam przyjemność (w końcu!) obejrzeć film Oppenheimer, który pokazuje życie tytułowego bohatera i jego pracę nad bronią nuklearną.
