Twój koszyk jest obecnie pusty!
Grok łagodnieje? Nowy model od xAI
xAI wprowadza Groka 4.1 – najnowszą wersję swojego modelu językowego. Firma deklaruje znaczącą poprawę w zakresie rozumienia intencji, spójności wypowiedzi oraz redukcji błędów, co ma przełożyć się na wyższą jakość interakcji z użytkownikami.

xAI wprowadza Grok 4.1 – nowy model ma wprowadzić bardziej naturalny i angażujący styl rozmowy, większą empatię (podobnie jak GPT 5.1) oraz kreatywność, przy jednoczesnym zachowaniu wysokiej wiarygodności odpowiedzi.
Co się zmieniło w praktyce?
Według xAI największe postępy dotyczą płynności dialogu, wyczucia kontekstu emocjonalnego i spójności osobowości. Model ma lepiej rozumieć subtelne intencje rozmówców, a jednocześnie pozostać szczery i maksymalnie pomocny. Te cechy uzyskano dzięki rozbudowanemu etapowi uczenia ze wzmocnieniem (reinforcement learning).
Twórcy obiecują też, że popracowali nad dwiema irytującymi cechami AI:
- Kłamanie: Model ma być bardziej odporny na presję i rzadziej mijać się z prawdą, nawet gdy próbujemy go do tego zmusić podchwytliwymi pytaniami.
- Przytakiwanie: Ograniczono tendencję bota do zgadzania się ze wszystkim, co napiszemy, tylko po to, by być miłym – nawet jeśli piszemy bzdury.
Dwa tygodnie cichych testów
Zanim oficjalnie ogłoszono premierę, xAI zrobiło mały eksperyment. Przez dwa tygodnie, od 1 do 14 listopada 2025 roku, część osób korzystających z serwisu rozmawiała już z nowym Grokiem, nawet o tym nie wiedząc. Wstępne wersje Grok 4.1 stopniowo obsługiwały coraz większy procent rzeczywistego ruchu. W ślepych testach porównawczych użytkownicy woleli odpowiedzi Grok 4.1 w 64,78% przypadków w stosunku do poprzedniej wersji produkcyjnej wersji.
Grok 4.1 plasuje się bardzo wysoko w popularnych rankingach takich jak LMArena, zarówno w trybie z dodatkowym rozumowaniem, jak i w szybkiej wersji bez myślenia.
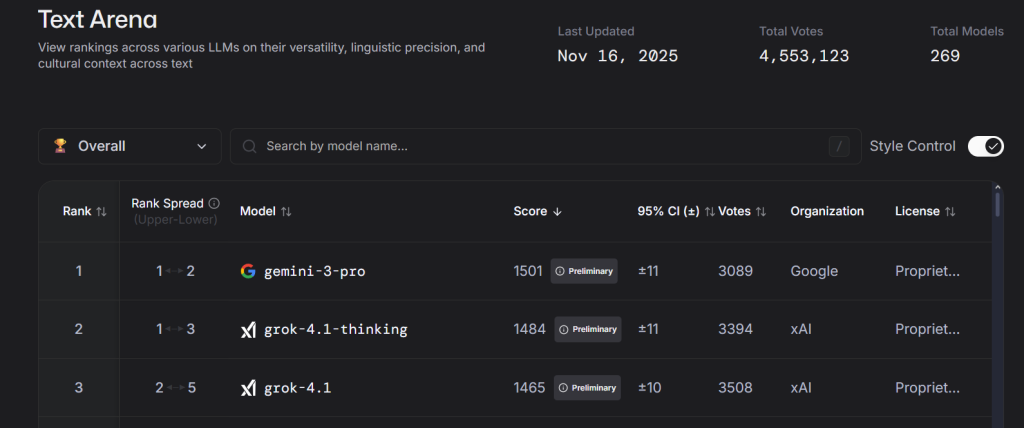
xAI szczególnie podkreśla postępy w zadaniach wymagających empatii i umiejętności interpersonalnych. Wewnętrzne testy miały pokazać, że Grok 4.1 lepiej rozumie, o co nam tak naprawdę chodzi, gdy zadajemy pytanie, i potrafi dostosować ton rozmowy.
Ma to być widoczne także w zadaniach kreatywnych. Kiedy poprosimy go o napisanie opowiadania czy maila, styl ma być bardziej spójny i mniej chaotyczny. W benchmarku EQ-Bench3 nowa wersja osiąga jedne z najwyższych wyników spośród publicznie dostępnych modeli. Podobnie dobrze wypada w testach kreatywnego pisania (Creative Writing v3).
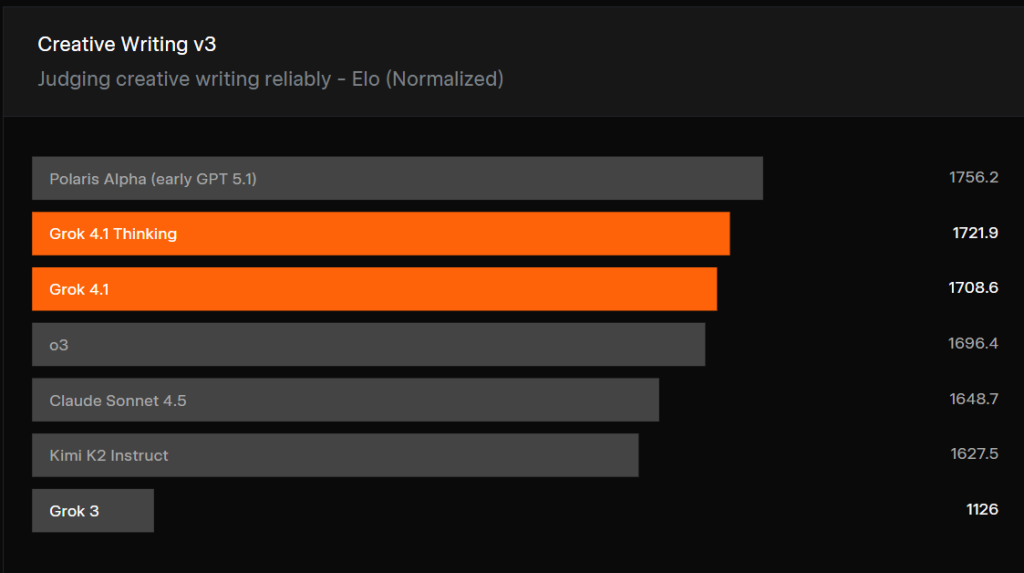
Mniej halucynacji
Każdy, kto korzystał z AI, wie, że modele lubią czasem popłynąć i zmyślić fakt lub dwa. xAI zapewnia, że wzięło ten problem na warsztat. Dzięki dodatkowym zabiegom w fazie post-trainingu Grok 4.1 ma popełniać zauważalnie mniej błędów faktograficznych w odpowiedziach na pytania informacyjne – zarówno w testach wewnętrznych jak i na publicznym benchmarku FActScore.
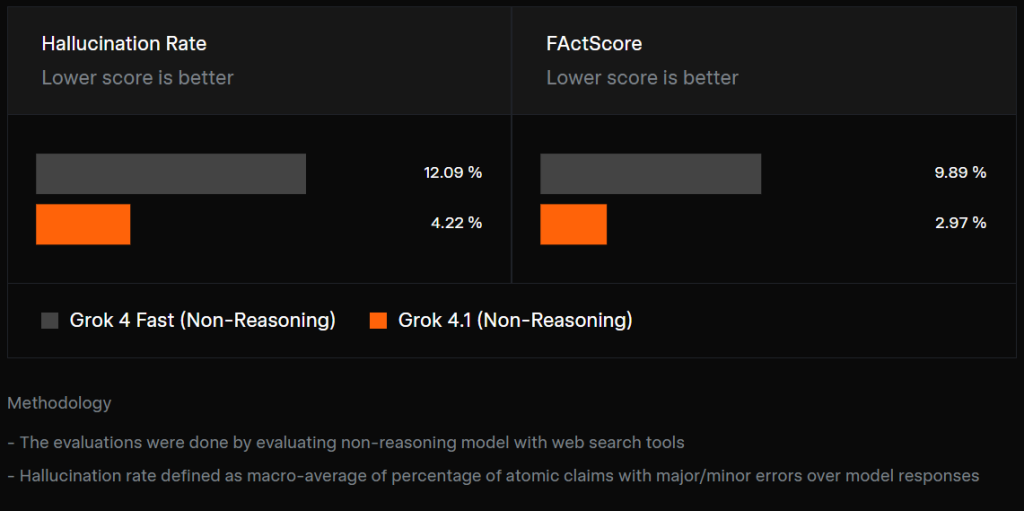
Bezpieczniej, ale nadal w stylu Groka
Model przeszedł rozbudowane testy bezpieczeństwa zgodnie z Risk Management Framework xAI. Grok ma odmawiać, gdy poprosimy go o coś nielegalnego (np. przepis na niebezpieczną substancję), ale nie powinien nas cenzurować w tematach, które są po prostu kontrowersyjne lub dyskusyjne.
Wygląda więc na to, że xAI próbuje trudnej sztuki: chce ucywilizować naczelnego buntownika wśród chatbotów, nie zabijając przy tym jego ducha. Czas pokaże, czy Grok faktycznie złagodniał, czy tylko nauczył się lepiej ukrywać swoje rogi przed cenzorami.

Share
You might be interested in
-
Premiera GPT-5.2. Nowa seria modeli do zadań specjalnych
OpenAI udostępnia serię GPT-5.2, stworzoną z myślą o profesjonalnej pracy. Według deklaracji twórców, nowe modele mają lepiej radzić sobie z kodowaniem, analizą danych i długimi dokumentami, popełniając przy tym znacznie mniej błędów.

-
Mistral 3: Premiera nowej generacji modeli open-weight
Mistral AI prezentuje rodzinę modeli Mistral 3. Obejmuje ona wariant Large w architekturze MoE oraz serię Ministral na urządzenia lokalne. Wszystkie modele udostępniono na licencji Apache 2.0.

-
Claude Opus 4.5 : nowa jakość w kodowaniu?
Anthropic prezentuje Opus 4.5 – model, który ma przewyższać inżynierów w testach technicznych, kosztując przy tym ułamek ceny poprzednika.

-
Nano Banana Pro: Precyzja, tekst i weryfikacja
Google wprowadza Nano Banana Pro – model oparty na architekturze Gemini 3 Pro. Nowe rozwiązanie oferuje zaawansowaną obsługę tekstu, kontrolę nad oświetleniem oraz wbudowaną weryfikację SynthID.
