

DeepSeek – a lurking tiger
The newest DeepSeek model offers advanced reasoning capabilities, comparable to top models like GPT-4, at significantly lower costs and less computational resource consumption.

DeepSeek is a Chinese company that recently released a series of language models in open source, including DeepSeek-V3 and two versions of a reasoning-oriented model: DeepSeek-R1-Zero (trained exclusively through reinforcement learning) and DeepSeek-R1 (which uses a multi-stage training approach). Even though new models are published somewhere in the world every day, this specific set literally shook the tech and business world for a moment, so much so that it stirred up the stock market. Why?

A transformer with a twist?
DeepSeek’s architecture is based on the classic transformer-type architecture (discussed in detail in “hAI Magazine” issue 1/2024), with the key difference that standard feed-forward layers have been replaced with MoE (Mixture of Experts) layers. In MoE layers, instead of a single feed-forward network, we have a set of experts (also feed-forward networks) and an advanced system that picks which experts will process a given token. This approach allows the model to achieve results comparable to leading proprietary models, all while maintaining computational efficiency.
Fun fact
MoE architecture was previously used in various language models. One of the first big models available to the public that used it was Mixtral, released in December 2023.
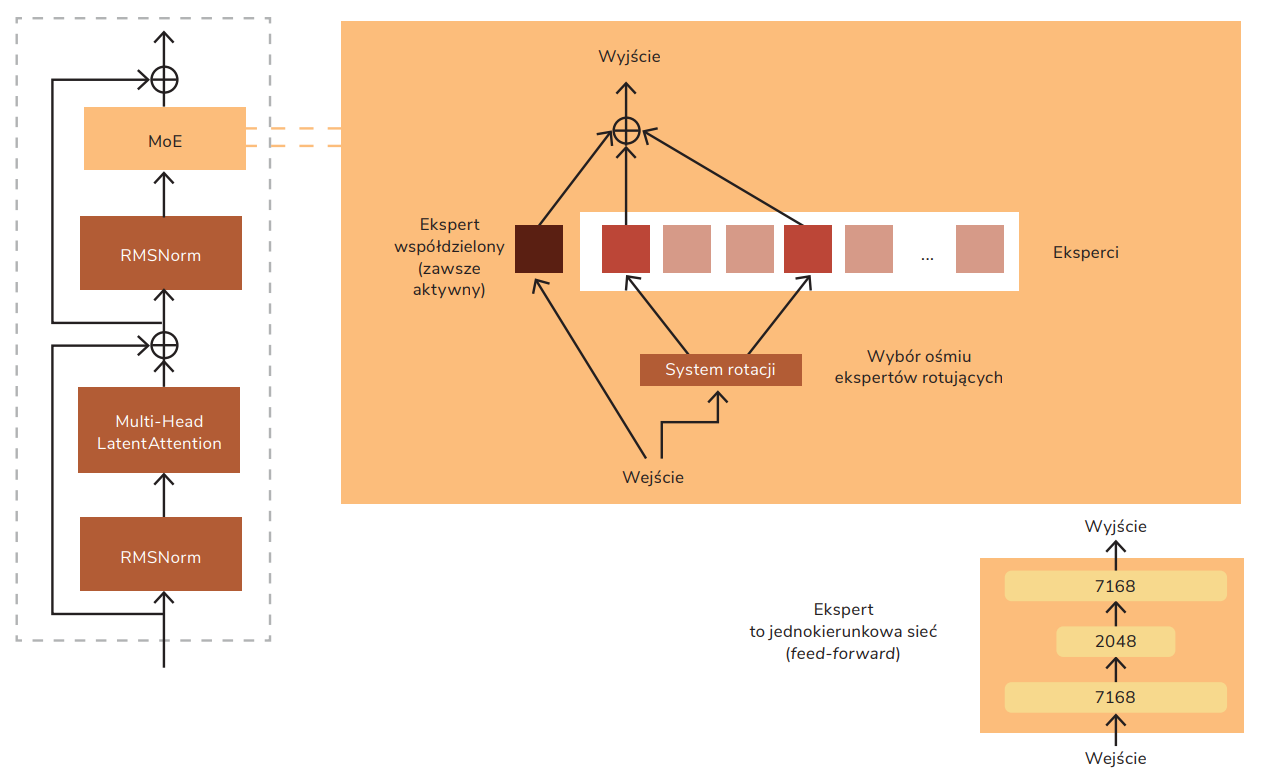
Figure 2. Simplified diagram from the article about DeepSeek-V3
How does this compare to the classic approach?
Classic transformers (e.g. Llama-2, GPT-3, BERT) consist of successive layers, each with a specific number of parameters.
While the model processes the token to calculate the result, all parameters are used – every parameter is active in each layer. This approach works, but compared to the MoE method, it’s expensive and inefficient.
In simple terms, it can be compared to having a group of experts: a car mechanic, a chef, a birdwatcher. Each of them has to make every single decision, even if it’s not related to their specialty.
In DeepSeek, for processing each token, only selected expert networks are used: first, we match experts to the token, and then we ask the question. This ensures that we don’t end up asking chefs or car mechanics about the nesting habits of storks.
What sets DeepSeek apart from Mixtral?
In the implementation, DeepSeek MoE uses an advanced rotation system with a key innovation in the form of an auxiliary-loss-free balancing strategy. In each of the 58 MoE layers – except the first three – the model picks nine experts to predict the next token: one shared expert and eight specialized. Every expert is a one-way network with a structure of 7168 → 2048 → 7168 neurons.
The expert selection involves determining the similarity between the token and the available experts, and then picking those that best match the input.
Similarity is determined by calculating the affinity score, which in turn involves comparing the input token (more specifically its vector representation) with the expert’s centroid. Mathematically, this is defined as the sigmoid function of the dot product of the token representation and the expert centroid.
8 out of 256 specialized experts are selected for predictions – those with the highest adjusted matching coefficient. On top of that, there’s always an active shared expert involved.
In every prediction, a shared expert helps ensure the stability and consistency of results, while specialized experts can focus on specific aspects of language processing.
Fun fact
During training, DeepSeek-V3 applies the expert bias mechanism – if an expert is used too often, their priority is decreased, and if too rarely, it’s increased. So it’s like in a restaurant where the manager watches how many tables are taken and assigns waiters to them on the fly.
Multi-Token Prediction
It’s also worth mentioning that the model uses the Multi-Token Prediction (MTP) technique, which predicts not only the second token, but also the one following it, improving prediction quality and decoding speed. We could compare this to how a chess player plans several moves ahead. DeepSeek-V3 predicts two such steps at once. In order to predict multiple tokens ahead, the model is expanded with what’s called MTP modules (neural networks). For example, if we want to predict three tokens ahead, we should add two extra MTP modules to the model architecture.
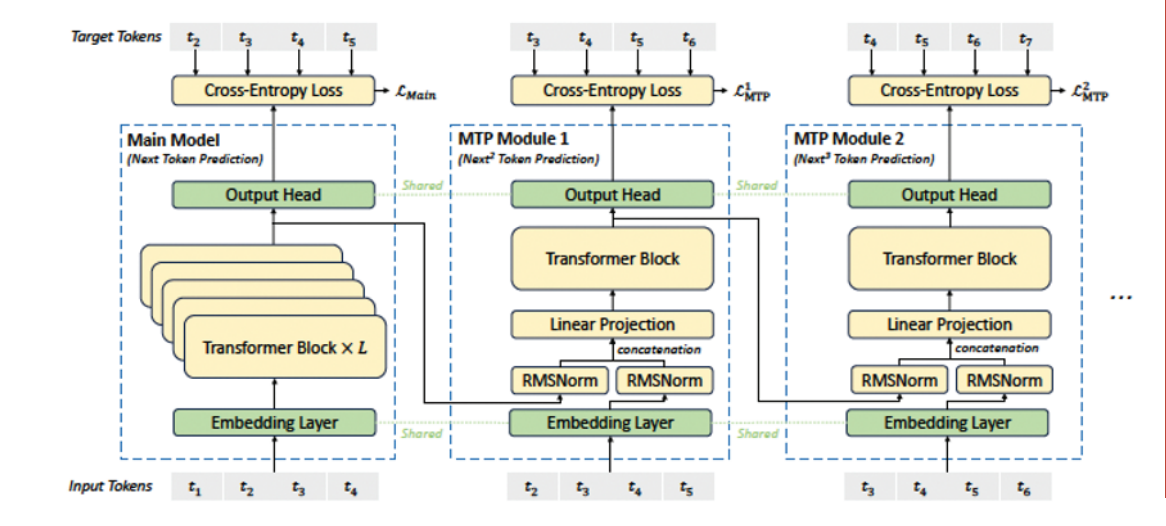
Figure 3. Original diagram from the article about DeepSeek-V3, with MTP
Example of expert rotation:
Experts are chosen separately for each input token. For example, for the sentence “Cats like math”:
| Token “Cats” | Token “like” | Token “math” |
| Receives its own set of 8 rotating experts and one shared for each layer. The set may specialize in animals, for example. | Receives a different set of 8 rotating experts and one shared, which may specialize in general words and verbs. | Receives another unique set of 8 rotating experts and one shared which may specialize in scientific and mathematical terms. |
Physical limitations
Even though the DeepSeek-V3 model has 671 billion parameters, thanks to the mentioned expert rotation system and running only selected ones, the model actually uses only 37 billion parameters at the same time. But that doesn’t mean you can just load that many into the memory. If you want the model to work properly, you should load all the parameters into the GPU because each input token will require a separate set for activation. So in reality, when using such a model, you’ll be using all its parameters, just not all at once.
Another limitation is that each token can only use experts from up to 4 nodes (GPUs). This means that even if experts are divided into more than 4 parts (e.g. a model loaded onto 8 GPUs), a single token can only use experts from 4 nodes. This limitation was introduced to optimize communication between GPUs.
This might mean that some of the often-used experts might not “make the cut” for a single common node. Therefore, DeepSeek came up with another solution.
How does high-load expert duplication work?
The system keeps an eye on how much the experts are used during operation. Every 10 minutes, the frequently used experts are identified, and their placement on nodes (GPU) is updated. The goal of these extra experts is to optimize the load during inference.
How to train a model to think?
Before performing a task, the DeepSeek models from the R (which stands for Reasoning) series “think” using the Chain-of-Thought approach, a well-known method for improving model performance. The standard approach to creating a model that can reason like this involves gathering a large set of training data with examples of tasks and the reasoning that precedes them – that’s the classic supervised training.
Prompt: |
Putting together such a training set would be super expensive. It would require hiring experts from various fields – they’d have to document their thinking process when solving problems, for example, when writing an algorithm or debugging code. Instead of this solution, the authors decided to use reinforcement learning (described in “hAI Magazine” issue 2/2024). In this approach, the model generates many different outputs and is rewarded for both the thought process and the correct answers.
The beauty of pure RL: DeepSeek-R1-Zero
The article proposed two types of regular rewards:
- Accuracy reward: given when the answer is correct – for instance, in math tasks where the model was supposed to deliver the result in a specific format (say: in square brackets) that could be automatically checked.
- Format reward: additionally, the model received a reward when it added its thought process between the <think> i </think> tags.
This method, based on rules, streamlines the training process. For contrast, in the original approach from the OpenAI article, PPO (Proximal Policy Optimization) and the “judge/critic” reward model are used. The reward model is usually a large language model – the same size as the trained model – that is used to evaluate the response generated by the model during training.
How to get rid of a critic
At DeepSeek, we have a set of rules and GRPO (Group Relative Policy Optimization) that estimate so-called “advantage points”, which means figuring out how much better or worse a particular action is compared to the baseline. How is this advantage calculated? By means of relative rewards within a small group of samples. A group is simply a set of several parallel responses generated by the model in response to the same input.
For each answer from the group a reward is given (e.g. for correctness). Next, the GRPO compares the response relatively to others in the group – better ones get a positive advantage and worse ones a negative.
What’s important, advantage points are normalized by:
- subtracting the average value of rewards in the group,
- dividing by the standard deviation of the group.
GRPO also uses the so-called “KL divergence” between the policy model and the reference model, which helps maintain stability during training.
Finally, we update the policy network by increasing the probability of those responses that turned out to be relatively better. This is how we can train the model skipping the costly judge’s opinions.
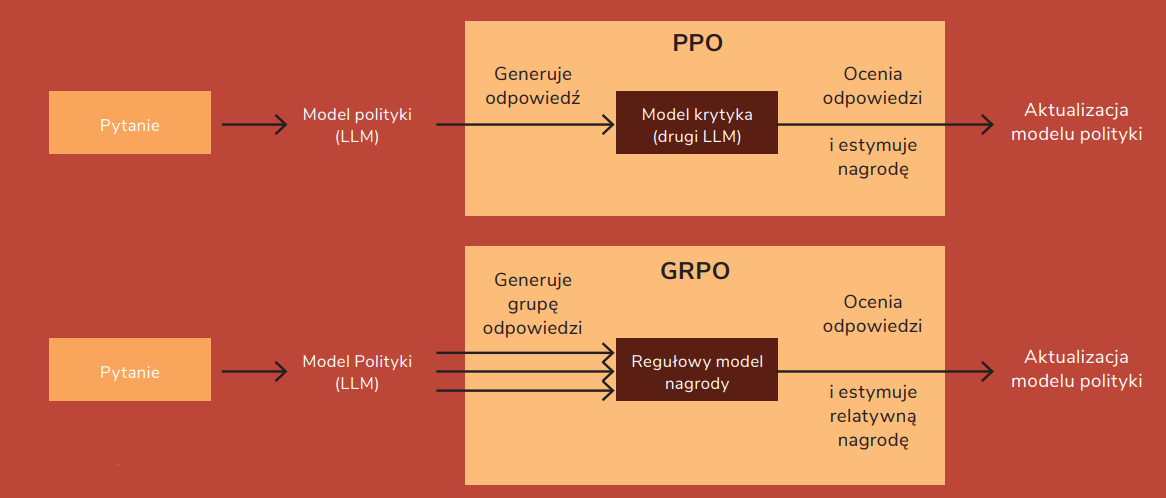
Figure 4. Simplified comparison of GRPO vs PPO (from DeepSeekMath)
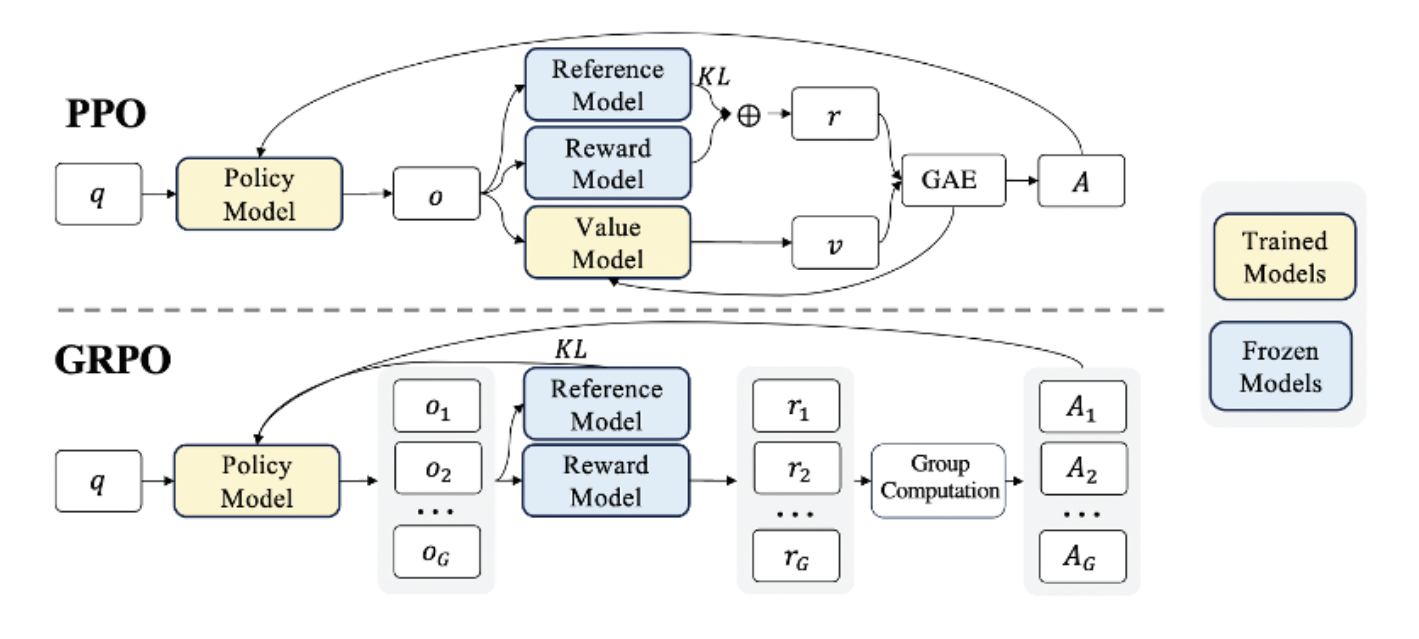
Figure 5. Original comparison of PPO/GRPO (from DeepSeekMath)
This approach speeds up training, but when it comes to the accuracy reward, it requires building a set with reference answers.
When the model has time to think
Authors emphasized that when the model had “more time to think”:
- The response lengths increased – the model initially generated simple thought processes, but over time they became increasingly longer.
- Experienced “epiphanies” – this triggered further self-reflection, and it automatically spent more time thinking about the problem, went back to previous steps, and verified their correctness or explored alternative approaches.
What’s particularly noteworthy, these behaviors appeared spontaneously – the authors didn’t program the model to specifically make “pauses” or experience “epiphanies.” These behaviors emerged naturally in the reinforcement learning process. Quoting the authors, such cultivated behavior simply “underscores the power and beauty of reinforcement learning,” and “serves as a reminder that RL has the potential to unlock new levels of artificial intelligence.”

Despite its good reasoning results, DeepSeek-R1-Zero had trouble with the readability of its responses and tended to mix languages. Meanwhile, chains of reasoning should be clear, consistent, and easy for the user to interpret.
If the model was trained entirely with RL, could it be worth improving reasoning performance or speeding up convergence by adding a small amount of high-quality initial data?
The answer to these problems was another approach, which was addressed in the DeepSeek-R1 model. It used RL (as before), but this time with a cold start, meaning a user-friendly initial dataset.
Multi-stage training is the key to success – DeepSeek-R1
Stage 1. Cold start + RL = reasoning process improvement
A cold start is just fine-tuning the model on previously prepared data (with long reasoning chains). The authors prepared thousands of such samples. They used the previous DeepSeek-R1-Zero and, with the help of few-shot prompting, generated examples, which were further improved by human annotators.
This iterative approach to training in creating reasoning models turned out to be more effective than pure reinforcement learning. But… the issue of mixing up languages still persisted.
The solution to this problem turned out to be… a new type of award – the language consistency reward, calculated as the ratio of the target language to all languages in the reasoning chain. The authors indicated that this approach slightly worsens results but improves user satisfaction.
But that’s not all. Since almost automatic data preparation helped every time, why wouldn’t it help in the next stage too?
Stage 2. Rejection sampling – the best of the best
The definitive concept? Another fine-tuning, but with more high-quality data. The authors took the model after the first phase of RL training, generated a large amount of responses to the same questions, and then applied the rejection sampling method. So, in other words – they chose only the best answers. For example, they rejected answers where languages were mixed, the code was unreadable or paragraphs turned out to be exceptionally long.
In tasks with unambiguous answers (like math problems), they simply checked if the result was correct. For more complex tasks, they used DeepSeek-V3 as a “judge” to evaluate the quality of answers.
Altogether, they collected around 600,000 examples related to reasoning were collected. Also, around 200,000 regular tasks examples that were not related to reasoning (e.g. “Hi!”) were added. This way, the model didn’t lose its basic skills, which could have happened if it only focused on reasoning.
Stage 3. The last touch – alignment (RL for all scenarios)
After removing lower-quality data, the authors felt that the model still needed an additional round of training – this time focused not only on reasoning, but also on overall usefulness and safety. Therefore, they introduced the second stage of reinforcement learning with several important modifications.
- Reward model: even though at first they avoided using LLM as a “judge”, they found it useful at the final stage. They argued that they hadn’t used it before because reward models often “cheat” during long training, require additional resources, and just complicate the whole process. Other awards (for linguistic consistency, format and correctness) remained unchanged.
- Two levels of assessing answers: the helpfulness is evaluated based on the final answer and the harmlessness is checked throughout the message (reasoning process + answer).
Additionally, the authors used DeepSeek-V3, kept a balance between usability and security, and made sure to include a variety of prompts containing tasks that require reasoning and tasks that don’t.
Results
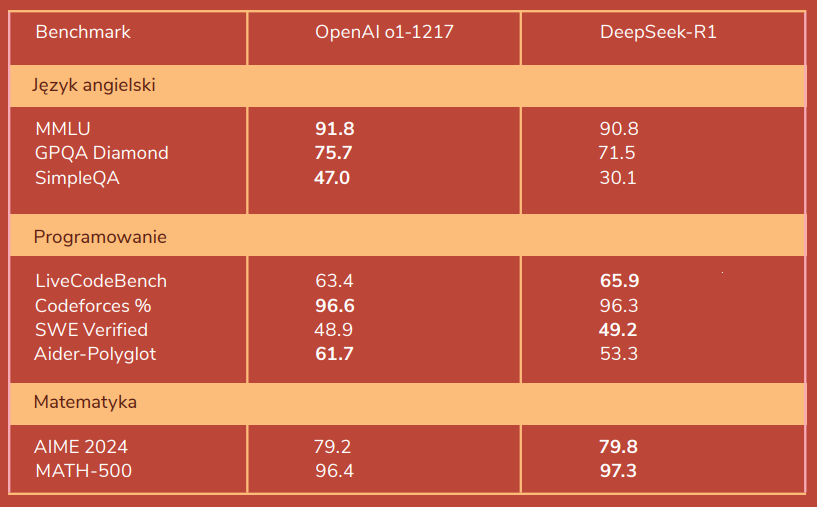
Why did DeepSeek make a global sensation? Because it achieved results comparable to the best models, generating lower training costs (showing that well-thought-out architecture and training strategy can be more important than pure computing power) while also being open-source.
Let’s compare the specific results of R1 vs o1:

Share
You might be interested in
🔒 Candidate rejected for facial expressions. What did the system assess instead of skills?
Can AI reject a candidate based on their facial expressions? A well-known recruitment support system did this for several years, and the world’s largest corporations used it. Today, similar practices are simply…


🔒 A calculator for minds or systemic laziness? The essence of the debate about AI in schools
While Asian schools are turning education over to algorithms en masse, we are still seeking a humanistic compromise. The skills of the entire next generation of workers depend on which model we…


🔒 Deepfakes in war. When the news anchor doesn’t exist
The war in the Middle East has been fought on the traditional and informational fronts since the beginning. And the latter has turned out to be the most intense test of deepfake…


🔒 Expert’s take: The hype is over, the real work begins
A 70-year-old woman at a birding meetup warns a friend that ChatGPT hallucinates. A lawyer is coding his own AI app. And after three years of working with almost a hundred companies,…

