

BERT – classically in fashion
In the beginning there was a word, followed by another, read forwards and backwards. The bidirectional encoder once entered the scene with flair and reigned for a long time – it only gave way to LLMs, but away from the glitz, it is still making a career to this day. Especially where stability and safety…
When we talk about language models, we primarily mean generative models, such as GPT, Claude or Gemini, whose task is to answer questions, execute commands or create content. Actually, language modeling doesn’t necessarily have to rely on text generation, as here modeling means developing a model (mathematical, probabilistic) that describes the language. When we take a closer look at the genealogical tree of language models, we can see that it divides into three main branches. In the first one, there are the generative language models we are all familiar with, based on decoders from transformer architecture. In the second one, models based on encoders that are not used for generating text, but for creating its representation (word and sentence vectors). Through unsupervised learning, they learn to “understand” the language and place sentences of similar meaning close to each other.
Encoders cannot function independently as assistants, but they are components of larger machine learning systems. The representations they create can be utilized in Retrieval Augmented Generation (RAG) systems, search engines or recommendation systems that could not function without a good text representation. Additionally, they lay the ground for machine learning models designed for specific tasks, such as classification or information extraction.
Although these are two alternative ways of creating language models, it would be unfair to say that decoder-based models have won the race. While the new model for text representation might not spark as much excitement as a new version of GPT or DeepSeek, they are simply tools for different purposes. Additionally, these systems, precisely because they are based on lighter models that do not generate text but rather create its representations, can operate locally with high efficiency and greater control.
From the end and from the beginning
One of the first language models based on encoders was BERT. It was developed by Google in 2018 (almost simultaneously with the first version of GPT). The name BERT stands for Bidirectional Encoder Representations from Transformers. The name essentially contains the most important features of the model:
- Bidirectional – the model analyzes the text simultaneously in both directions – from start to finish and from finish to start, instead of processing it sequentially like generative models. Unlike GPT-like models, it does not generate text, but creates its representation, so it is trained to use both left-to-right and right-to-left context. It can grasp better the context of the words, as it considers both earlier and later parts of the sentence when creating this representation.
- Encoder – the model uses transformer architecture. A standard transformer consists of two parts – an encoder and a decoder. While the encoder is responsible for creating representations of the input sequence, the decoder’s task is to use these representations to generate text.
- Representations from Transformers – the model is tasked with creating text representations. The result of BERT’s actions are contextual word and sentence vectors that encode the meaning of concepts. These are the representations that are used as input for other NLP systems.
How BERT learns to understand language
While GPT models are trained to learn how to predict the next word (Causal Language Modeling), Bert approaches the task of understanding language in a slightly different way. It uses two mechanisms: Masked Language Modeling (MLM), which involves masking random words in a sentence and guessing what stood in their place, and Next Sentence Prediction (NSP), which involves guessing whether two sentences form a logical sequence. It’s worth noting that these are so-called pretext tasks. It’s not about creating a model that perfectly fills in the gaps in sentences. The model simply has to learn to indirectly create good text representations, and with these tasks, we force it to learn the language.
Masked Language Modeling
In this task, a few words are randomly selected and replaced with the special symbol [MASK]. For example, the sentence “The cat sleeps on the couch” can be transformed into “The cat [MASK] on the couch”. The model must guess which word was replaced by the [MASK] symbol. In this case, the model tries to predict that the missing word is “sleeps”. To correctly predict the missing word, the model must understand the context of the entire sentence. Thanks to this, it learns how words are connected to each other and how their meaning depends on the context.
Here you can see the bidirectionality of BERT – to predict the missing word, the model uses both the left-to-right context and the right-to-left context. It doesn’t read the text from start to finish, but processes the entire sequence at once.
Technically, predicting a masked word is a classification based on the representation of the [MASK] token that was created by BERT. Through the attention mechanism of the transformer, this representation is iteratively enriched with information from neighboring words, and at the model’s output, we get the [MASK] token vector that considers the context of the entire text.
Next Sentence Prediction
The model receives pairs of sentences. One pair can consist of two consecutive sentences (e.g., “The cat sleeps on the couch. It’s tired after a whole day of playing”), and the other consists of randomly chosen sentences that are not related (e.g., “The cat sleeps on the couch. The car is parked on the street”).
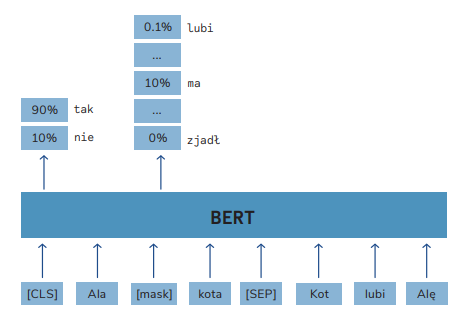
The model must determine whether the second sentence is a logical continuation of the first one or not (binary classification). In the first case, it should determine that the sentences are related, and in the second, that they are not.
The classification is based on the representation of the [CLS] token. This is a special artificially-added token that’s designed to contain a generalized representation of the entire sentence. The task itself forces the model to make the [CLS] token represent the entire sentence, because in order to perform the classification based solely on this token, the model inevitably has to learn to encode in it all the information about the sentence.
Application in machine learning
| At the beginning, we said that BERT-type models are used in natural language processing systems, so it’s worth describing what such applications look like. Thanks to the tasks described above, BERT creates a text representation that can be used in many ways in machine learning systems. The most common applications can be divided into a few main categories: 1. Text classification – using the token representation [CLS], which —as we already know— contains aggregated information about the entire text, we can build a classifier for different tasks, such as sentiment analysis, spam detection or document categorization. We just have to add one classification layer on the [CLS] representation. 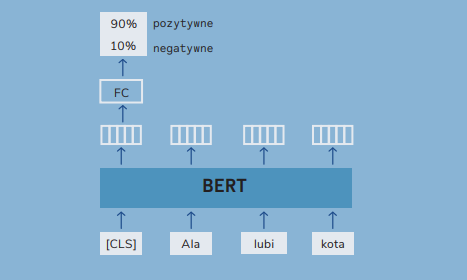 2. Information extraction – representations of individual tokens can be used to mark sections of text (token classification), which is useful in tasks such as recognizing proper names —Named Entity Recognition (NER)— or extracting key information from documents. 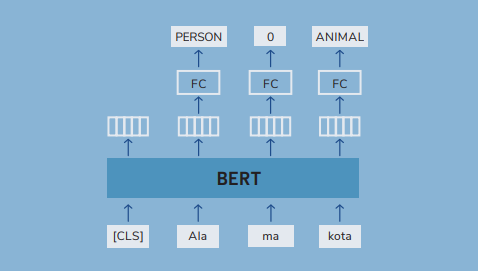 Search systems – representations created by BERT enable semantic text comparison. Instead of comparing texts based on the words they contain, we can compare their vectors, which allows us to capture semantic similarities even when different words are used. 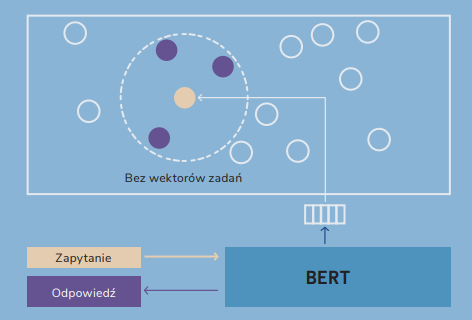 |
Poles are not geese; they have their own model
In Poland, the HerBERT model was developed by Allegro in 2021. It was trained on over 20 million texts from collections such as the National Corpus of Polish Language, Wikipedia, and Modern Poland Foundation. Its architecture was very similar to the original BERT, but it included a tailored tokenizer and omitted the NSP task (which turned out to be unnecessary, as other studies have also shown).
Another example of a Polish model is Polish RoBERTa, developed by the National Information Processing Institute – National Research Institute. It is larger than HerBERT and was trained on a more extensive data set, which resulted in better outcomes.
These are just two of many models that were specifically developed for the Polish language. You can find more, for example, in the ranking Comprehensive List of Language Evaluations (Kompleksowa Lista Ewaluacji Językowych – KLEJ), the Polish version of The General Language Understanding Evaluation (GLUE).
Oldie but goodie
As I mentioned before, models based on encoders are still used to create text representations. Although they usually no longer rely solely on the BERT model itself, but on newer variants of its architecture, tasks such as MLM are still being used.
At the end of 2024, an updated version of the BERT model named ModernBERT appeared. It differs from its predecessor primarily by having a longer context length – it supports up to 8192 tokens compared to 512 in the BERT model, which facilitates better processing of longer documents and complex queries. Additionally, it introduces improvements in the architecture of the model itself, such as the use of Rotary Position Embeddings (ROPE), GeGLU layers, and the Flash Attention mechanism, which enhance the efficiency and stability of training. This model is also trained on a more diverse dataset, which improves its performance in tasks related to programming language. ModernBERT achieves better results than the popular DeBERTaV3 model, which until now had won the most competitions on the Kaggle platform. Besides, ModernBERT uses five times less memory than DeBERTa.

Share
You might be interested in
🔒 Candidate rejected for facial expressions. What did the system assess instead of skills?
Can AI reject a candidate based on their facial expressions? A well-known recruitment support system did this for several years, and the world’s largest corporations used it. Today, similar practices are simply…


🔒 A calculator for minds or systemic laziness? The essence of the debate about AI in schools
While Asian schools are turning education over to algorithms en masse, we are still seeking a humanistic compromise. The skills of the entire next generation of workers depend on which model we…


🔒 Deepfakes in war. When the news anchor doesn’t exist
The war in the Middle East has been fought on the traditional and informational fronts since the beginning. And the latter has turned out to be the most intense test of deepfake…


🔒 Expert’s take: The hype is over, the real work begins
A 70-year-old woman at a birding meetup warns a friend that ChatGPT hallucinates. A lawyer is coding his own AI app. And after three years of working with almost a hundred companies,…

