

Is Bielik-R getting ready to fly?
“Thinking” models known as R type are now pretty much standard in all the leading families of large language models. Our Polish Bielik is also keeping its finger on the pulse and is starting to create a version that will be able to perform logical reasoning in Polish.

The concept of language models capable of “thinking” became popular with the introduction of OpenAI’s model o1. Models like these analyze the problem for a while before they give an answer. They generate a chain of thought that helps them choose the right direction in solving tasks, which increases their chances of providing the correct solution.
Just like other LLM models, the Polish language model Bielik was trained on huge amounts of text data. The first stage was pre-training, which means learning to predict the next token based on the input text. The choice of subsequent phases in model creation depends on the strategy adopted by the creators – usually it’s instruction fine-tuning. Training stages can include, among others, reinforcement learning (RL) techniques. One of the most effective methods is Reinforcement Learning from Human Feedback (RLHF), which entails a human evaluating the RL results. This solution was popularized by OpenAI as part of training ChatGPT. This process allows for more precise control over the model’s behavior and to adjust the form and content of responses to the recipient’s preferences. We decided to use the now typical method of reinforcement learning in the process of training the Bielik model. Since R type models (the “reasoning” ones) have become the global standard, we asked ourselves: can we create a model that will generate chains of thought in Polish? Will it be ready to leave the lab and take the form of a full-fledged Bielik-R model?
| Instructions | Which is the capital of Poland? | Preference rating [0-5] |
| Model’s response | Warsaw. | 3 |
| The capital of Poland is Krakow. | 0 | |
| The capital of Poland – Warsaw – is located in the middle of Poland by the Vistula River. Warsaw has been the capital since 1596, when King Zygmunt III moved the capital from Krakow to Warsaw. | 4 | |
| Warsaw is the capital of Poland. | 5 |
Table 1. User preferences. Evaluation can reflect the answer’s correctness and style (the ratings indicate a preference for a correct answer expressed in a full sentence, but not overly detailed).
How does RLHF work?
Before we dive into the details related to training and implementing the Bielik thinking model, let’s discuss the human evaluation technique (RLHF) that started it all. As the name suggests, the heart of the method is information about human preferences. In the model training process, it shows how to formulate responses to be truly useful and better meet user expectations.
In a nutshell, the RLHF training process consists of three main steps:
- Gathering user preferences data – the model generates multiple responses which are then evaluated by people.
- Training the reward model – based on ratings, a reward model is created which predicts the quality (preference value) of future responses – reinforcement learning relies on a system of punishments and rewards. We’ll be using it in the training process. It should be mentioned that this stage is often skipped because there are a lot of ready-made reward models. Unfortunately, the vast majority of them aren’t effective enough in Polish.
- Training the rewards model – based on ratings, a reward model is created which predicts the quality (preference value) of future responses – reinforcement learning relies on a system of punishments and rewards. We’ll be using it in the training process. It should be mentioned that this stage is often skipped because there are a lot of ready-made reward models. Unfortunately, the vast majority of them aren’t effective enough in Polish.
In RLHF training, a commonly used algorithm is Proximal Policy Optimization (PPO). It allows for improving models by fine-tuning them, but in a way that they don’t deviate too far from the original version. The model follows the user’s defined preferences but still performs its basic function (e.g., solving math problems). However, the PPO method is complex. During training, it uses several model instances, such as policy, value, reward, and reference models, which significantly increases the chances of training instability (as we update up to three models). Also, this method requires a lot of computational resources (compared to other methods) and extends the training time. An additional issue with the Polish language adaptation is the need to use a high-quality reward model, which is currently lacking in the market.
Recently, a lot of alternative methods have popped up that can boost the training efficiency. Among them, you’ll find examples like KTO (Kahneman & Tversky’s Prospect Theory Optimization), REINFORCE, RLOO (REINFORCE Leave One-Out), ReMax, and many more.
While creating the conversational version of the Bielik model, various reinforcement learning techniques were tested. It resulted in a significant improvement in the quality of generated responses (confirmed by multiple tests). Ultimately, though, the best results were achieved using the Direct Preference Optimization Positive (DPO-P) method – a simplified RLHF method that eliminates the need for training a separate reward model. In DPO-P, user preferences are directly embedded into the standard responses of the instructional data (for a given instruction, there’s a preferred and a rejected response), which simplifies and speeds up the fine-tuning, besides ensuring stability and high performance of the training process. You could say that this method derives from RL, but due to its nature, it’s closer to classic supervised learning methods where both input data and expected output are provided simultaneously.
DeepSeek introduces GRPO
DeepSeek has definitely livened up the already fast-paced world of AI. The R series model introduced a bunch of training process improvements and significantly cut down the costs of creating models. Additionally, it presented two different training processes that result in “thinking” models – DeepSeek-R-zero and DeepSeek-R1. In both cases, the Group Relative Policy Optimization (GRPO) approach was used. This is another method that has expanded the family of reinforcement learning methods.
The GRPO method is based on the concept of policy optimization for groups of generated responses. Unlike standard methods like PPO, which evaluate each one separately, GRPO compares responses in groups generated for the same task (prompt) by normalizing rewards within that group. Even though the model is primarily trained on mathematical or logical tasks, its reasoning is improving in other areas, like creative writing. Besides, GRPO significantly reduces resource needs during training, although the necessity to generate response groups adversely affects training time.
Bielik-R – the thinking Bielik
Just a few days after the release of the DeepSeek-R model, we started intensive research on adapting GRPO training methods to our native language. DeepSeek models currently generate thought chains in English and Chinese. At the same time, it was announced that in the future they will offer support for other languages. The aim of our research was to create a model that formulates “thoughts” exclusively in Polish.
The main challenges that arose at the beginning of the project were due to a lack of Polish training data. However, it turned out that it’s easy to adapt English instructions – we used publicly available math tasks. Initially, it was a collection called GSM8K (Grade School Math 8K). In the following experiments, we tackled much more complicated math and logic tasks. Another issue was the initial lack of support for the GRPO method in popular libraries used for distributed model training (using a large number of GPUs). It was no small feat to also obtain reliable information on adapting the training method to languages other than English.
GRPO training process in Bielik
How does GRPO work? The method is based on generating several answer options for one task, and comparing them to evaluate which answer is the best. Next, the model is updated based on the relative differences in the quality of answers generated within the group, which helps to more effectively steer the model’s policy towards generating preferred responses. Let’s move on to the simplified description of the GRPO method.
Step 1. Task selection
During learning, the algorithm selects a query from the training data, which consists of the task content and the solution (usually a number or a mathematical expression). For example: “What is the result of 2+3–4*0.5?”. The expected answer is 3.
Step 2. Generating a group (set of n) answers
The model generates a set of various answers. When training Bielik, we generated – depending on the experiment – from 8 to 16 answers. Examples:
"The result of 2+3–4*0.5 is <3>."
"Four."
"Answer: <2>.”
"The answer is 3."
"<3>"
Step 3: assigning reward values to answers
Rewards steer the model’s learning process, determining the quality of the responses generated by it. They are expressed in numbers on continuous or discrete scales. Usually, the correctness of answers is verified by means of rules – for example, you can check whether the answer is a number or whether it’s correct. The reward can also be determined using a metamodel, although experiments indicate that this approach sometimes leads to training instability (we introduce noise to the evaluation).
Examples of reward types introduced during the Bielik training in GRPO:
- Rewards for solving the task correctly. The expected answer is 3. If it’s correct, we give 2 points (reward), and if it’s incorrect, 0 (penalty).
- Rewards for the answer format. The model responds in CoT format, for example it generates thinking section tags <think ></think> or formats the response <3> (in triangular brackets) properly. This principle is assessed using an appropriate rule, and its result can range from 0 (incorrect format) to 0.5 (full compliance).
- Rewards for linguistic consistency. That’s the style, length of description, format, etc. The number of definitions of reward functions (that is, what we evaluate the model for) can be large – the only limitations are the creators’ imagination and the verification possibilities.
Example of response evaluation:
"The result of 2+3–4*0.5 is <3>." – correct and well-formatted answer: 2.0 + 0.5 -> 2.5
"Four." – incorrect and poorly formatted answer: 0.0 + 0.0 -> 0.0
"It's <2>." – incorrect, but well-formatted answer: 0.0 + 0.5 -> 0.5
"The solution is 3.” – correct, but poorly formatted answer: 2.0 + 0.0 -> 2.0
"<3>"– correct and well-formatted answer: 2.0 + 0.5 -> 2.5
Step 4. Comparison of answers within the group (group advantage)
Rewards are then normalized within each response group. We calculate the advantage of each answer compared to the group, so the model doesn’t learn on absolute reward values, but on relative differences between different answers generated for the same task. Answers that are better than the average group get higher scores. We support competition within the group so that the model generates increasingly better responses.
Step 5. Policy update with clipping
We limit the impact of individual responses on the policy update. If a new policy gives too much probability, cutting prevents excessively favoring this answer.
Step 6. KL-divergence regularization
Then, we limit the deviation of the new policy from the previous (reference model) to maintain training stability. This involves calculating the distance between the policy model distributions and the original model (KL Divergence). This element of the loss function protects the model from a significant change of “character”, such as generating content that gives maximum reward but alters the model’s original purpose.
Step 7. Determining the loss function values and updating the model weights
Finally, we calculate the function value and update the model weights using backpropagation. This is the standard procedure carried out during AI model training.
We have noticed that GRPO provides effective opportunities to optimize models in tasks requiring reasoning and multi-stage information processing.
Formula for GRPO loss function:
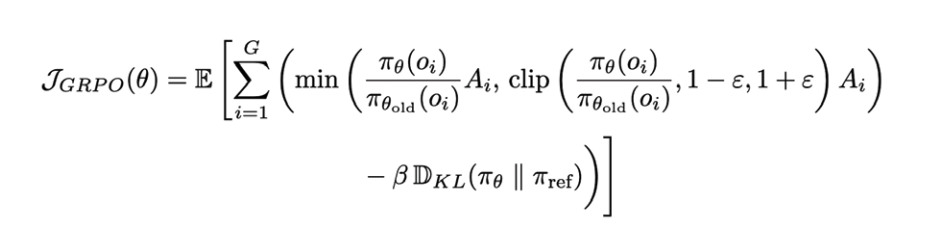
Formula for determining the answer quality in a group:
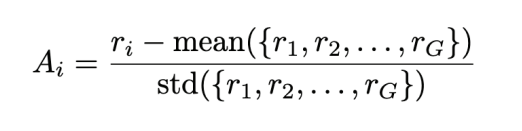
Observations and training insights of the Bielik model
We successfully completed the first attempts to adapt Bielik to the R model, that is, the “thinking” one. As part of this endeavor, several prototypes were created, each differing in terms of expression style, which was directly related to the reward policies defined during training. The main difference was in the thought sequence’s structure – from very short (step-by-step solution) to long monologues containing verifications of the reasoning sequence (“let’s verify the solution”, “let’s check”, “let’s simplify”). Creating a class R model definitely gives promising results and sets the direction for our further research.
During training with GRPO, we were surprised to see Bielik shaping its own way of solving problems. This indicates the model’s ability to self-organize and develop its own decision-making strategies. During training, you could observe the evolution of chains of thoughts. This process unfolded gradually over time. The model was looking for a way to achieve the highest score awarded by the evaluation function. For some rules (e.g., response formats), Bielik discovered them quickly. In other cases, he had to generate a very large number of different responses to ultimately adapt to the preferences defined by the reward function.
The model generated content that reflected self-improvement – “flashes of thought”. As if, during its reasoning, it began to realize that its train of thought was leading to an incorrect solution, and it sighed in surprise: “Aha!” These turning points often changed its further problem-solving method. In most cases, they led to correct results.
Encouraging the model to generate long responses (by defining a reward function that promotes longer chains of thought) for simple tasks led to generating unnecessary content of low substantive value and thus to the model providing incorrect solutions. For harder problems, Bielik naturally generated much longer thought sequences.
While experimenting, we made changes to the evaluation rules. The more complex the function (in terms of the number of evaluated response elements), the faster the model found a way to “bypass” the rules and started maximizing the reward, unexpectedly leading to achieving unpredictable effects (reward hacking effect).
We see that class R models should be built on “strong” base models – high-quality models confirmed by numerous reliable measurements. We also conducted adaptation tests on smaller versions of the Bielik-1.5B model, but the quality of their thought sequences was significantly different from the quality generated by the Bielik-11B model.
What’s next for the Bielik-R model?
Creating the Bielik-R prototype is a crucial step in developing Polish language models capable of reasoning. Implementing the GRPO method allowed to create a model that not only generates responses, but also analyzes its own solutions, learning optimal decision-making strategies. The experiment results showed that the model can adapt its way of thinking to the problem’s nature, as well as go through a self-improvement process, which is a promising feature for future applications.
Our experiences show that thinking models can significantly improve the quality of generated content and can be used in various areas – from education, through AI assistants, to more advanced data analysis systems. The first attempts to create a “thinking” model are just the beginning of this journey.
Our next steps include further improving Bielik’s reasoning mechanisms and optimizing the reward function in the GRPO training process. We also plan to expand the range of training data with more diverse types of tasks, which will allow the model to develop reasoning skills in various fields of knowledge. Developing the Bielik-R model is a significant step towards more advanced AI systems in Polish that not only generate answers, but also “think” in our native language.






Share
You might be interested in

🔒 The illusion of a digital fortress. How the foundations of security crumbled
Artificial intelligence can already independently bypass two-step verification and generate attacks in fractions of a second. We’ve entered the Machine Speed era, in which even the most advanced defense systems are doomed…

-
🔒 The end of the free silicon illusion. AI priced like electricity
The first half of 2026 is the moment when Silicon Valley stops subsidizing access to artificial intelligence. The magical $20-per-month barrier is no longer a flat rate for everything, and the AI…


🔒 Whose is your twin?
Imagine a scene from the near future. You go to the doctor with chest pain. Instead of immediately referring you for additional tests, the doctor runs a simulation on your “digital twin”…

-
🔒 Mythos versus logos: about fear and the sickle
On April 7, Anthropic announced something unusual. A new AI model called Mythos is reportedly so dangerous that the company has chosen not to make it publicly available. Access is being granted…
