

Few-shot learning – Recognize a labrador… even though you barely know it
If you want to teach your model to make accurate forecasts but you only have a few labeled examples, try using the few-shot learning method.

Standard supervised learning is super effective, but it can be impractical – it’s tough to get labeled training examples because of high costs or the limited availability of existing samples. One promising attempt to solve the lack of labeled data is few-shot learning, which allows models to efficiently learn and generalize knowledge based on just a few training examples.
What is few-shot learning?
Few-shot learning is a machine learning framework where the AI model learns to make accurate predictions by training on a very small number of labeled examples. This solution is usually applied to train models in classification tasks when there’s not enough data. Its opposite is traditional supervised learning, which normally uses hundreds or thousands of labeled data in multiple rounds (epochs) of training to teach AI models how to recognize data classes. Let’s consider a simple example. You want to build a model that will tell you whether a picture shows a golden retriever or a labrador retriever, but you only have 25 pictures to work with.
You have a limited number of examples and labels assigned to them, based on expert knowledge that determines whether a given image shows a golden retriever or a labrador retriever. The model has to learn to tell these breeds apart just from a few samples, using key features like fur length, ear shape and body proportions.

Figure 1. A set of dog pictures that can be used to train few-shot learning models to learn to recognize new classes with a limited number of examples.
When you only have a few labeled samples, training a model from scratch with supervised learning – especially a model with huge number of parameters – often leads to overfitting. Models like convolutional neural networks (CNN) used in computer vision and transformer-based networks used in natural language processing (NLP) are examples of that. The model might achieve good results on test data, but not so great on real-world data. Gathering enough data to avoid overfitting can be a real challenge in training models.
Few-shot learning is defined by the nature of the learning problem, not by the application of a specific method or model structure. It can use a wide range of algorithms and neural network architectures – most methods rely on transfer learning, metalearning or a combination of both. Few-shot learning can also be used for regression tasks, but most of the literature on FSL focuses on classification applications.
Transfer learning
Transfer learning methods focus on adapting a pre-trained model to learn new tasks or classes of data that weren’t previously considered.
Transfer learning offers a handy solution by applying useful features and representations that the model has already been trained on. One of the simpler solutions is fine-tuning a classification model to do the same task for a new class using supervised learning on a small number of labeled examples.
More complex methods of transfer learning adapt a pre-trained neural network by changing its architecture, for example by replacing or retraining the outer layers where the final classification happens, while still keeping the inner layers that are responsible for feature extraction. Freezing (or otherwise, regularizing weight changes) all layers except the outer ones helps to prevent “catastrophic forgetting” of previously acquired knowledge. This significantly speeds up learning in the few-shot context.
Transfer learning turns out to be most effective when the initial model training is similar to the new task. For example, a model trained on classifying different dog breeds generalizes well to previously unseen breeds after fine-tuning with a small number of labeled samples. This is because the filter weights used by the neural network for convolution are already optimized to capture important features for animal classification, like ear shape, fur length and body proportions. However, using few-shot learning to train the same model for vehicle recognition will yield less satisfying results if it was previously trained on recognizing animal breeds.
Fine-tuning a previously trained model for a new classification task with limited data.
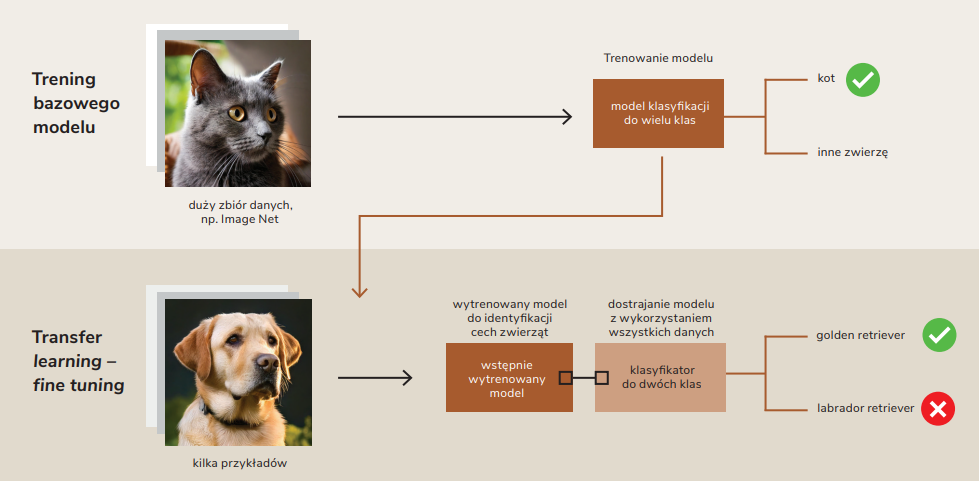
Figure 2. Fine-tuning a previously trained model for a new classification task with limited data.
Metalearning
Unlike transfer learning, where the classifier is pre-trained on many classes and then fine-tuned for specific tasks (and the training set includes the same classes that will appear during testing), metalearning takes a broader and more general approach. One method is prototype networks, which don’t learn specific categories, but rather how to categorize new classes based on a few examples. Instead of remembering individual samples, the model calculates their “prototypes”, which are average representations of the given classes. New images are then categorized based on how far they are from these prototypes in the feature space.
The main goal is to train a model that, over many training episodes, will learn to assess the similarity level between data points from different classes – even those it hasn’t seen before. The knowledge gained this way can then be used to solve more specific tasks, like classification.
Instead of the classic split into training and test sets, in prototype networks the model trains over many episodes. In each episode, we pick N classes, with each class containing only K examples, making what’s called a support set. The model is tested on new examples from the same classes, creating a query set. First, we calculate representations for the support set using a neural network. Next, we figure out the average of all representations for each class – this result becomes the prototype of that class. When classifying new examples, we calculate their representations and measure the distance from each prototype. We assign the example to the class whose prototype is closest in the feature space.
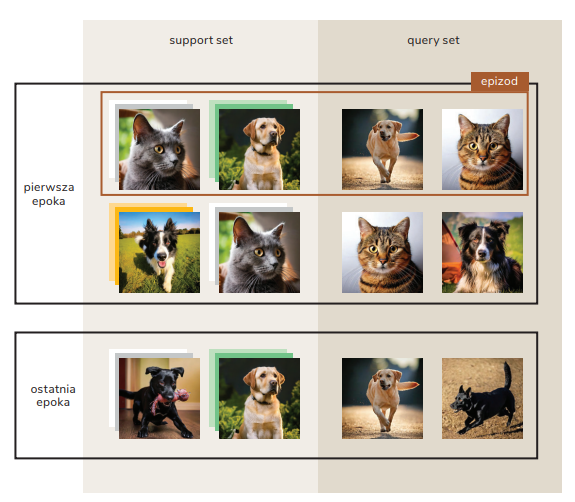
Figure 3. The model learns to classify based on episodes made up of a support set and a query set.
This technique is really effective for the Omniglot data set, which includes 1623 different classes of handwritten characters, and each class has just 20 examples! It turns out this model gains high accuracy pretty fast.
A promising method
Few-shot learning is a promising method for tackling the problem of limited labeled data, and it’s used in lots of areas like image processing, NLP and biomedical data analysis. In the future, further development of metalearning and transfer learning could boost even more the effectiveness of models trained on a limited number of examples.

Share
You might be interested in

🔒 The illusion of a digital fortress. How the foundations of security crumbled
Artificial intelligence can already independently bypass two-step verification and generate attacks in fractions of a second. We’ve entered the Machine Speed era, in which even the most advanced defense systems are doomed…

-
🔒 The end of the free silicon illusion. AI priced like electricity
The first half of 2026 is the moment when Silicon Valley stops subsidizing access to artificial intelligence. The magical $20-per-month barrier is no longer a flat rate for everything, and the AI…


🔒 Whose is your twin?
Imagine a scene from the near future. You go to the doctor with chest pain. Instead of immediately referring you for additional tests, the doctor runs a simulation on your “digital twin”…

-
🔒 Mythos versus logos: about fear and the sickle
On April 7, Anthropic announced something unusual. A new AI model called Mythos is reportedly so dangerous that the company has chosen not to make it publicly available. Access is being granted…
